http://www.zhihu.com/question/26010353/answer/34468073
不走索引的情况下,尽量把条件放到程序里面
http://www.zhihu.com/question/26010353/answer/34468073
不走索引的情况下,尽量把条件放到程序里面
http://www.cnblogs.com/kunpengit/archive/2012/03/14/2395792.html
http://blog.163.com/qiangyongbin2000@126/blog/static/775178192010102432819113/
1 | struct redisServce { |
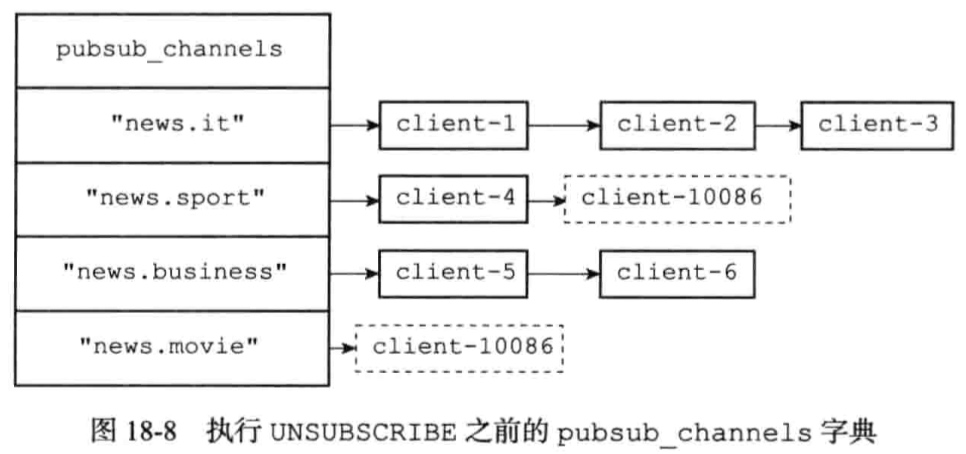
client-10086: SUBSCRIBE “news.sport” “news.movie”
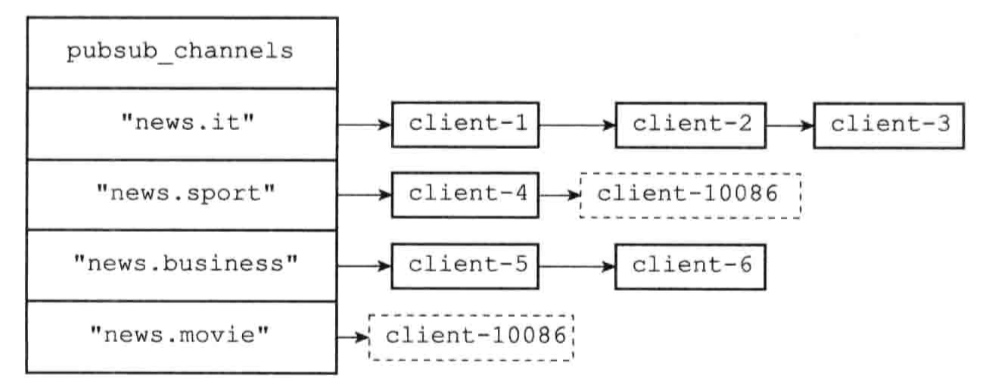
client-10086: UNSUBSCRIBE “news.sport” “news.movie”
1 | struct redisServer{ |
client-9: PSUBSCRIBE “news.*”
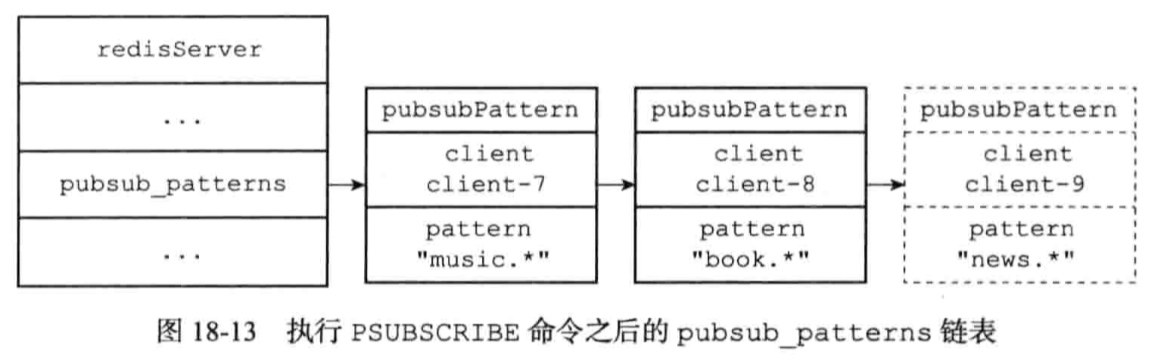
PUBSUB NUMPAT
Redis订阅信息丢失问题
征服 Redis + Jedis + Spring (三)—— 列表操作
通过MULTI、EXEC、WATCH等命令来实现事务功能。
并发运行共享内存地址,需要对共享变量进行协同。
dubbo服务接口新增返回值和方法,消费者先升级,调用服务报错:
1 | Caused by: com.alibaba.dubbo.remoting.RemotingException: Fail to decode request due to: RpcInvocation [methodName=dataGrid, parameterTypes=[class com.xxx.ProductInfoDTO, null], arguments=null, attachments={dubbo=2.8.4, input=463, path=com.xxx.product.ProductService, version=0.0.0}] |
dubbo服务接口新增返回值和方法,生产者先升级,消费者调用服务报错:
消费者报错:
1 | Caused by: com.alibaba.dubbo.remoting.RemotingException: Fail to decode request due to: RpcInvocation [methodName=dataGrid, parameterTypes=[class com.xxx.ProductInfoDTO, null], arguments=null, attachments={dubbo=2.8.4, input=462, path=com.xxx.ProductService, version=0.0.0}] |
生产者报错:
1 | 2016-10-15 14:54:35,787 [New I/O worker #12] WARN in [com.alibaba.dubbo.rpc.protocol.dubbo.DecodeableRpcInvocation.decode(DecodeableRpcInvocation.java:120)] - [DUBBO] Decode argument failed: com.esotericsoftware.kryo.KryoException: Unable to find class: #path, dubbo version: 2.8.4, current host: 172.22.23.214 java.io.IOException: com.esotericsoftware.kryo.KryoException: Unable to find class: #path at com.alibaba.dubbo.common.serialize.support.kryo.KryoObjectInput.readObject(KryoObjectInput.java:127) at com.alibaba.dubbo.rpc.protocol.dubbo.DecodeableRpcInvocation.decode(DecodeableRpcInvocation.java:116) at com.alibaba.dubbo.rpc.protocol.dubbo.DecodeableRpcInvocation.decode(DecodeableRpcInvocation.java:74) at com.alibaba.dubbo.rpc.protocol.dubbo.DubboCodec.decodeBody(DubboCodec.java:138) at com.alibaba.dubbo.remoting.exchange.codec.ExchangeCodec.decode(ExchangeCodec.java:134) at com.alibaba.dubbo.remoting.exchange.codec.ExchangeCodec.decode(ExchangeCodec.java:95) at com.alibaba.dubbo.rpc.protocol.dubbo.DubboCountCodec.decode(DubboCountCodec.java:46) at com.alibaba.dubbo.remoting.transport.netty.NettyCodecAdapter$InternalDecoder.messageReceived(NettyCodecAdapter.java:134) at org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:70) at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:564) at org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:559) at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:268) at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:255) at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:88) at org.jboss.netty.channel.socket.nio.AbstractNioWorker.process(AbstractNioWorker.java:109) at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:312) at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:90) at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178) at org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108) at org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745) Caused by: com.esotericsoftware.kryo.KryoException: Unable to find class: #path at com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:138) at com.esotericsoftware.kryo.util.DefaultClassResolver.readClass(DefaultClassResolver.java:115) at com.esotericsoftware.kryo.Kryo.readClass(Kryo.java:641) at com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:752) at com.alibaba.dubbo.common.serialize.support.kryo.KryoObjectInput.readObject(KryoObjectInput.java:125) ... 22 more Caused by: java.lang.ClassNotFoundException: #path at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1387) at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1233) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:274) at com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:136) ... 26 more |
消费方也升级之后,则可以正常调用服务。
dubbo服务接口新增返回值和方法,消费者先升级,服务可以正常调用,读取接口新增的值也正常,返回为空。
dubbo服务接口新增返回值和方法,生产者先升级,消费者调用服务正常。
测试发现,在版本一直的情况,生产者使用kryo,消费者使用hessian2,或者生产者使用hessian2,消费者使用kryo,都可以正常调同,所以在版本一致的情况可以和好对生产者和服务者的序列化协议进行切换。
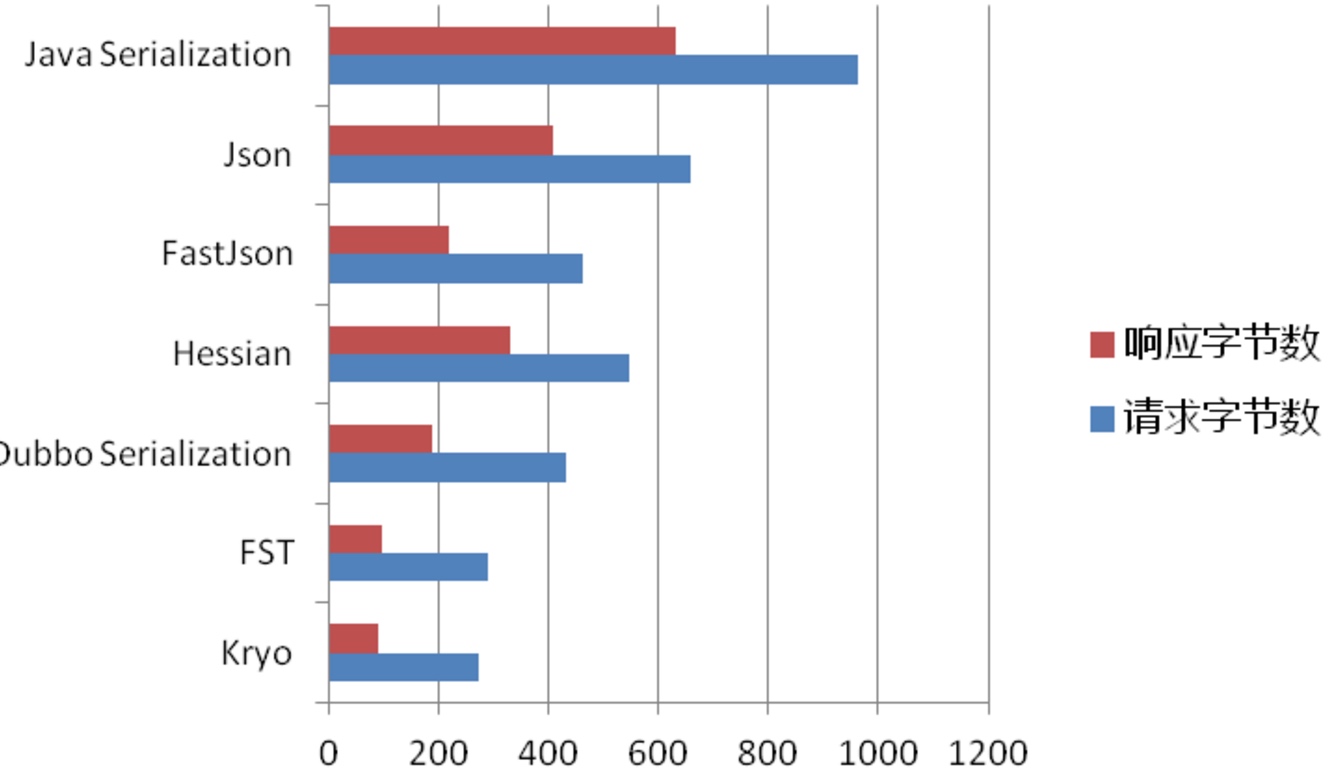
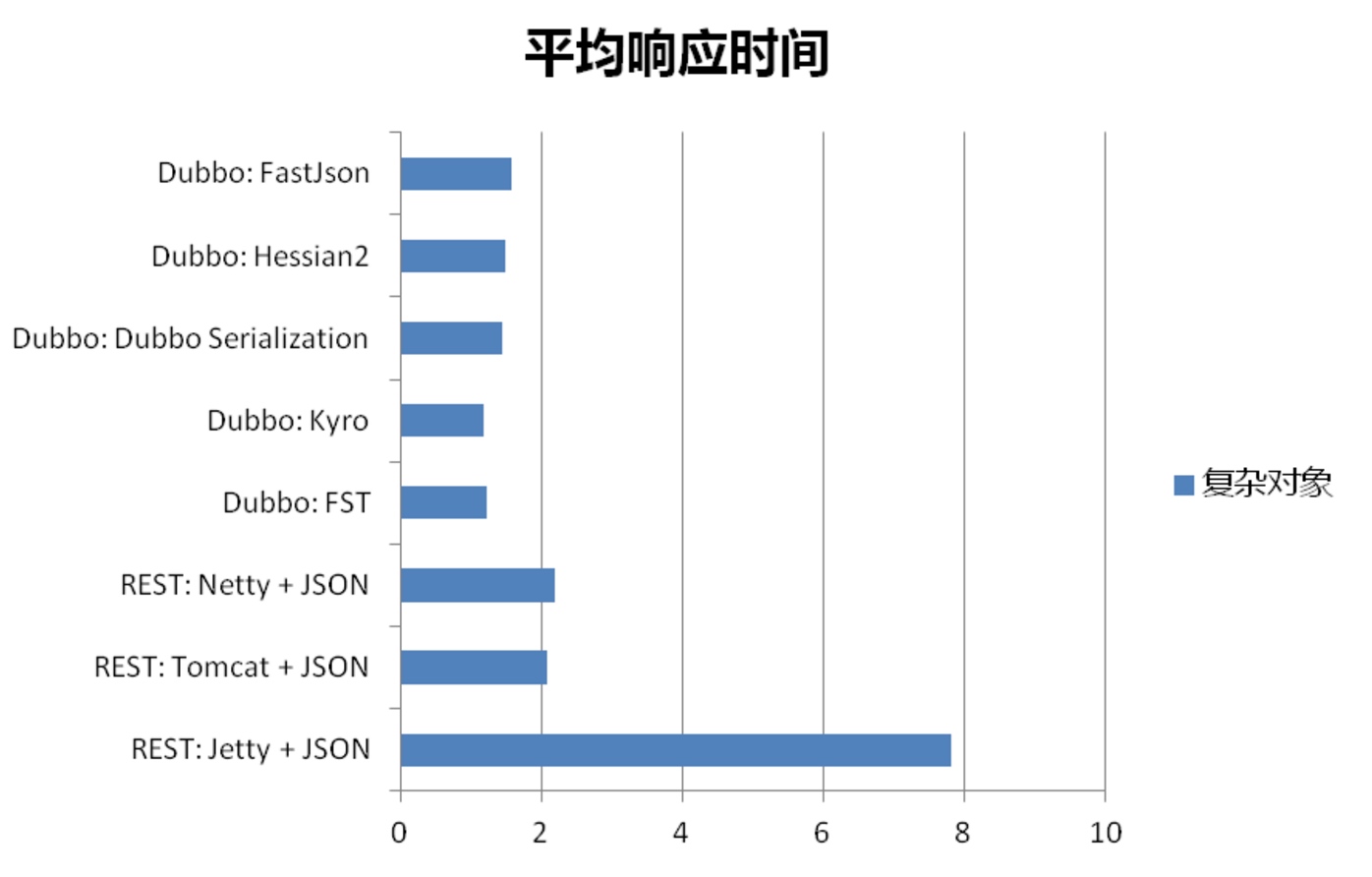
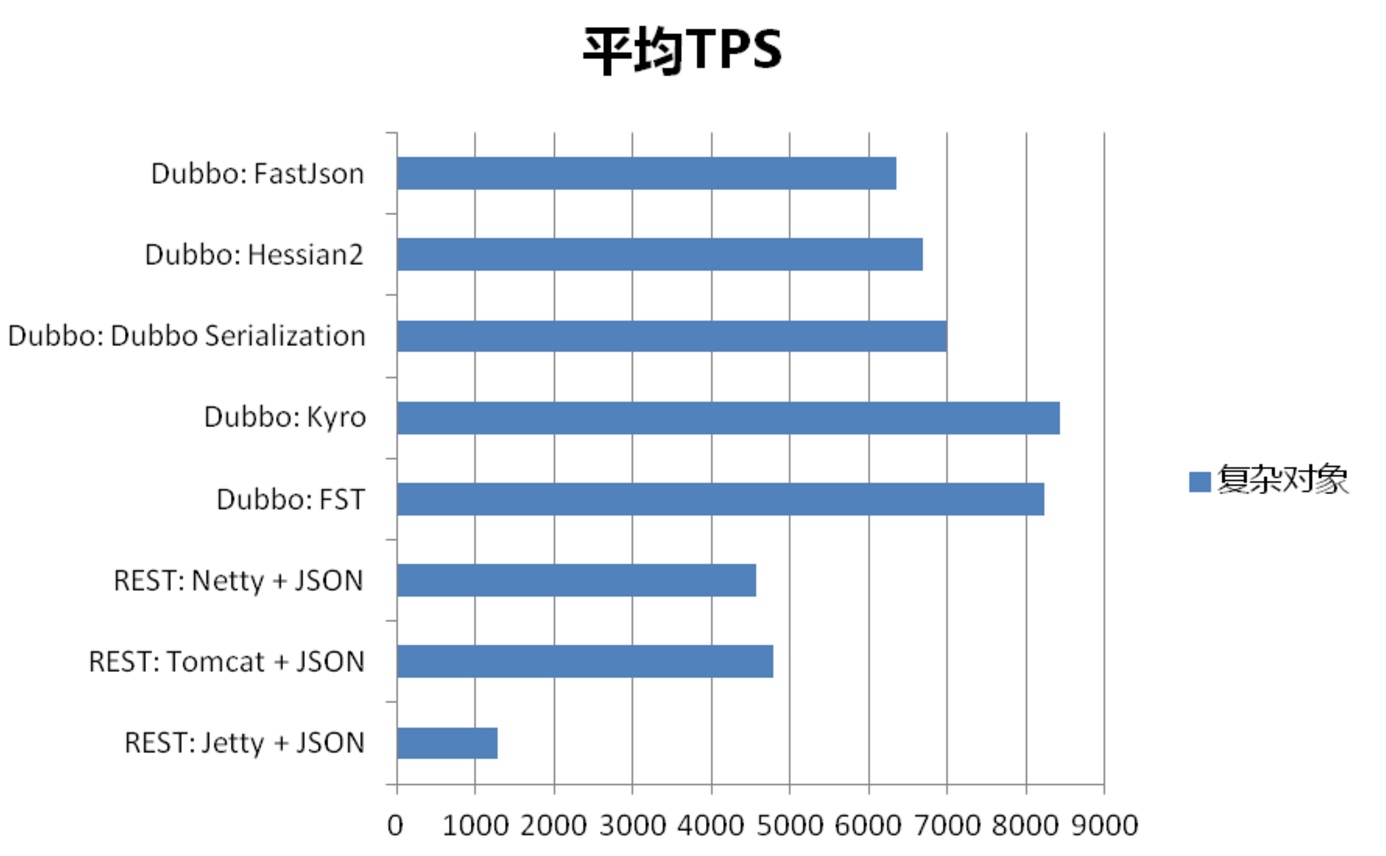
可以发现,使用kryo协议,无法保证接口返回值添加属性时升级过程中的兼容,而hessian则可以兼容。
Kryo平均响应时长,每秒事务数,带宽节省等相对来说,的确是比较出众,当Kryo在Dubbo中应用足够成熟之后,使用其作为序列化的确是一个不错的选择。
编写正确的并发程序的关键在于对共享的、可变的状态进行访问管理。
内存可见性,你可以通过显示的同步,或者利用内置于类库中的同步机制,来保证对象的安全发布。
为了确保跨线程写入的内存可见性,你必须使用同步机制。
指令重排会对多线程共享变量产生影响。
只要数据需要被跨线程共享,就进行恰当的同步。
多线程分别执行get set,而没有对变量进行同步,指令重排导致过期的数据,改为同步:

没有声明为volatile的64位数值变量(double和long),在多线程中共享,也可能不是安全的,(JVM运行将64位的读或写划分为两个32位的操作)。
锁不仅仅是关于同步与互斥的,也是关于内存可见的,为了保证所有线程都能够看到共享的、可变变量的最新值,读取和写入线程必须使用公共的锁进行同步。
加锁可以保证可见性与原子性;volatile变量只能保证可见性。
使用volatile的条件:
一个对象在尚未准备好时就将它发布,这种情况称作逸出。

一旦一个对象逸出,你就要假设存在其他的类或线程可能误用它,无论是出于恶意还是粗心。这是使用封装的强制原因:封装使得程序的正确性分析变得更可行,而且更不易偶然地破坏设计约束。
不要让this引用在构造期间逸出。
为了保证对象状态有一个一致性视图,我们需要同步。
不可变对象可以在没有额外同步的情况下,安全地用于任意线程;甚至发布它们时亦不需要同步。
安全发布对象的条件:
从一开始就设计一个线程安全的类,比在以后再将这个类修改为线程安全的类要容易的多。
线程安全的类中封装了必要的同步机制,因此客户端无需进一步采取同步措施。
无状态对象一定是线程安全的(不包含任何域和其他类的引用,只有线程局部变量)
int类型也非原子,++count包含了读取,修改,写入的操作序列。
UnsafeCountingFactorizer
最常见的竞态条件类型是:先检查后执行操作,即通过一个可能失效的观测结果来决定下一步的动作。
LazyInitRace
单利模式的懒惰模式如果没有加同步,多线程可能产生不同的对象实例
要避免竞态条件问题,就必须在某个线程修改该变量时,通过某种方式防止其他线程使用这个变量,也就是让其变成原子操作(两个线程互斥)
在实际情况中,应该尽可能使用现有线程安全对象如AtomicLong来管理类的状态。
为了保护状态的一致性,要在单一的原子操作中更新相互关联的状态变量。
synchronized块,是互斥锁(mutual exclusion lock,也称作mutex)。
内置锁是可重入的,防止一下这种情况导致的死锁:
重入锁的请求是基于每个线程的,而不是每个调用;通过为每个锁关联一个请求计数和一个占有它的线程实现的。
如果用同步来协调访问变量,每次访问变量时,都需要同步,每次访问变量都需要同一个锁。
Kryo bug貌似比较多,Java数据类无法兼容老版本,在系统快速迭代的项目中,这是影响比较大的;
Hessian序列化字节量和耗时稍微高一点,但尚能接受。
序列化方多一个不用的属性,反序列化方少了这个属性,可以正常反序列化;
反序列化方多了一个属性,反序列化的时候会报错;
1 | javax.net.ssl.SSLProtocolException: handshake alert: unrecognized_name |
Java 7引进了SNI(Server Name Indication 是为了解决一个服务器使用多个域名和证书的SSL/TLS扩展。既是,在连接到服务器建立SSL连接之前先发送要访问站点的域名(Hostname),这样服务器根据这个域名返回一个合适的证书。)的支持,默认是开启状态的,这个会导致在建立SSL连接握手的时候需要获取到访问连接的正确的虚拟域。要使用SNI,需要客户端和服务器端同时满足条件(客户端和服务器端都支持SNI,客户端发送了正确的域名,服务器端也做了相应的SNI配置)。
为了解决这个问题,可以手动的设置一下jsse.enableSNIExtension属性,暂时把SNI禁用掉,设置方法:
1 | com.thoughtworks.xstream.converters.ConversionException: Cannot construct ClassXXX as it does not have a no-args constructor : Cannot construct java.util.RandomAccessSubList as it does not have a no-args constructor |
升级JDK版本,导致xstream不兼容,解决方法:
2016-08-03 10:21:39.972 [schedulerFactoryBean_Worker-2] WARN com.yeepay.common.utils.CallbackUtils - connection error : java.lang.RuntimeException: Could not generate DH keypair
javax.net.ssl.SSLException: java.lang.RuntimeException: Could not generate DH keypair
at sun.security.ssl.Alerts.getSSLException(Alerts.java:208)
at sun.security.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1904)
at sun.security.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1862)
把低版本的bcprovexclude掉:
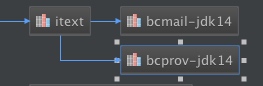
引入新的版本:
1 | <dependency> |
SSL handshake alert: unrecognized_name error since upgrade to Java 1.7.0
Xstream no-args constructor error
快钱报错:javax.net.ssl.SSLProtocolException: handshake alert: unrecognized_name解决
垂直切分:按照业务进行切分
水平切分:对于大表,进行分表分库,把数据散落在不同的数据库里面,对于数据增长相近,在业务上也比较紧密的表,两个Shard可以放到同一个数据库节点上,散列取一样的模。
垂直或水平切分之后,原来的关联关系需要打断,重新逐个查询组装数据。如何路由到Shard节点去查询或者更新数据也是关键。
不同之处:
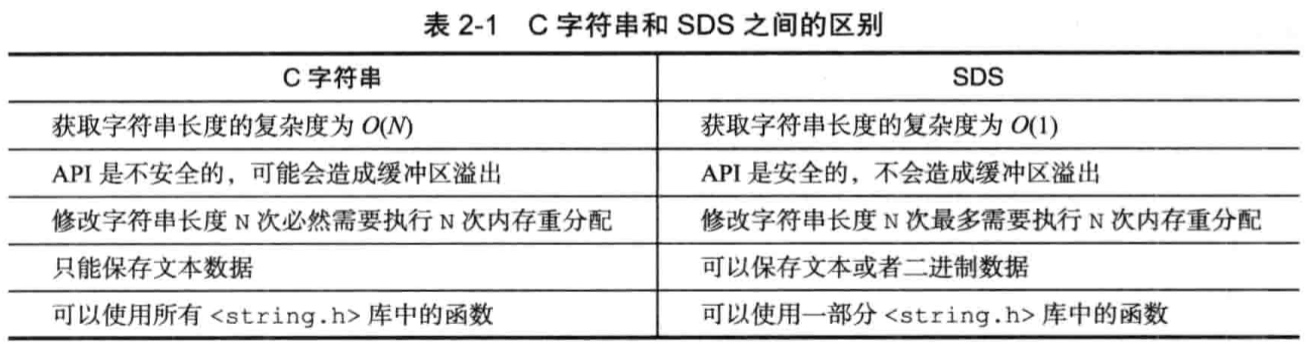
用于:
列表键,发布与订阅,慢查询,监视器等功能也用到了链表;

不同类型的值Redis数据库,对数据库的增删改查操作也是构建在对字典的操作之上的。字典还是哈希键的底层实现之一
Redis使用Hash表作为底层实现
Hash表结构
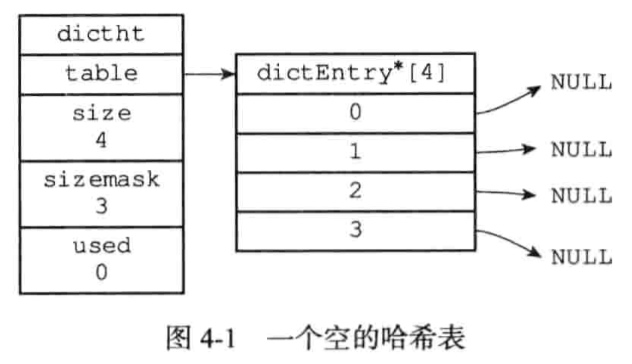
值可以是一个指针,或者是一个unit64_t整数,或者int64_t整数
字典结构
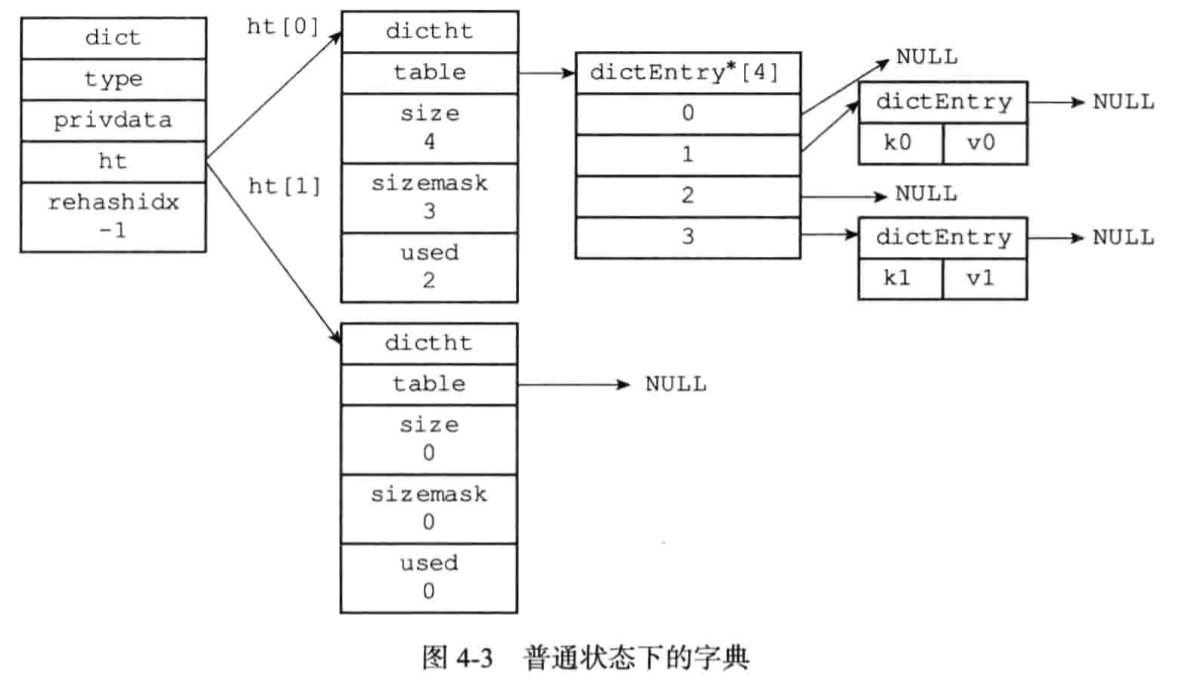
ht[1]只会在对ht[0]进行rehash的时候使用。rehashidx记录rehash的进度。
当字典被用作数据库底层实现或者哈希键的底层实现时,Redis使用了MurmurHash2算法来计算键的哈希值;
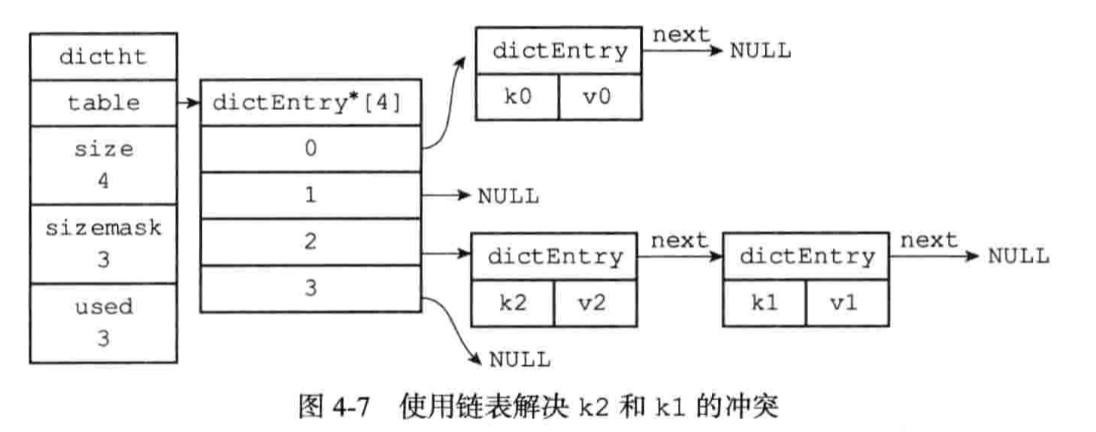
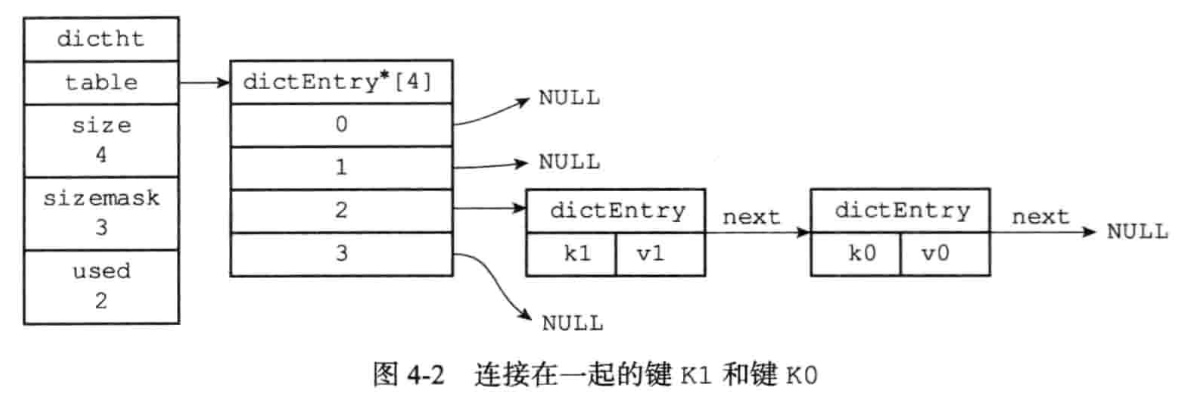
程序总是将新节点添加到链表的表头未知
随着哈希表的键值对主键增多,为了让负载因子维持在一个合理的范围,当键值对太多或者太少时,需要对哈希表的大小进行相应的扩展或收缩,通过rehash(重新散列)操作来完成.
rehash过程:
为了避免rehash对服务器性能造成影响,服务器不是一次性将ht[0]全部hash到ht[1],而是分多次,渐进式地进行。在rehash期间,删除,查找,更新会在两个哈希表上进行,而新增则写入ht[1]。
跳跃表支持平均O(logN),最坏O(N)复杂度的节点查找,大部分情况下,跳跃表的效率可以和平衡树相媲美,而跳跃表的实现比平衡树更简单。
Redis使用跳跃表作为有序集合键的底层实现之一;集群节点中用作内部数据结构。
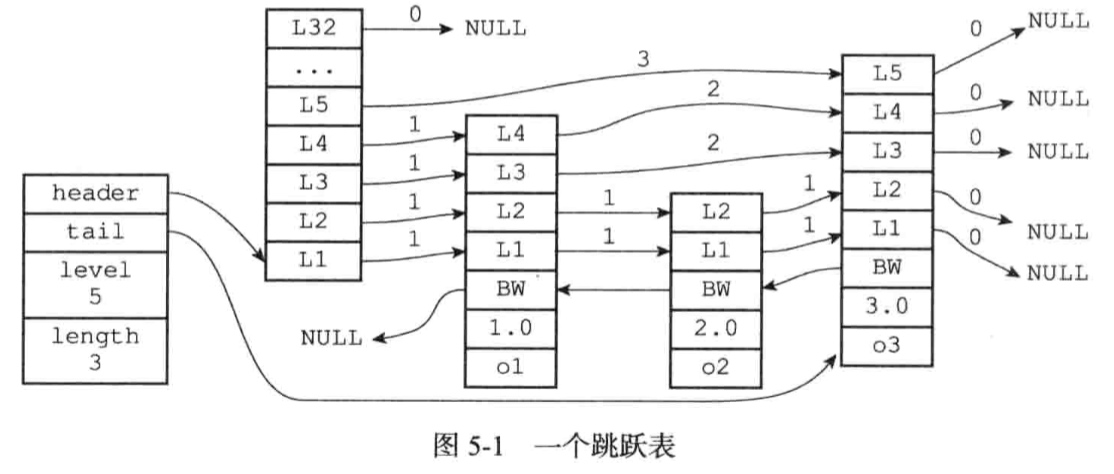
从表头到目标节点,所累计的跨度代表了目标节点在跳跃表中的排位;
后退指针
分值和成员:跳跃表中所有节点都是按照分值从小到大排列的;成员是一个指针,指向一个SDS字符串。
整数集合是集合键的底层实现之一(当一个集合只包含整数值的时候,并且元素数量不多时)。
各个项在数组中按值的大小从小到大有序地排列,并且不包含任何重复项;
contents数组保存的类型取决于encoding中的值,而不是int8_t;
新元素的类型比现有的所有元素的类型都要长的时候会进行升级;每次添加新元素,都有可能导致升级,所以复杂度为O(N)。
C语言为了避免类型错误,通常不会把不同类型的值放到同一个数据结构里面,通过升级,可以灵活添加不同类型的整数,而不必担心出错;
在适当的是时候,才升级,节约了内存;
整数集合不支持降级操作;
当一个列表只包含少量列表项,并且每个列表项要么是小整数,要么是长度比较短的字符串,Redis就会使用压缩列表来做列表键的底层实现。
压缩列表是Redis为了节约内存而开发的;
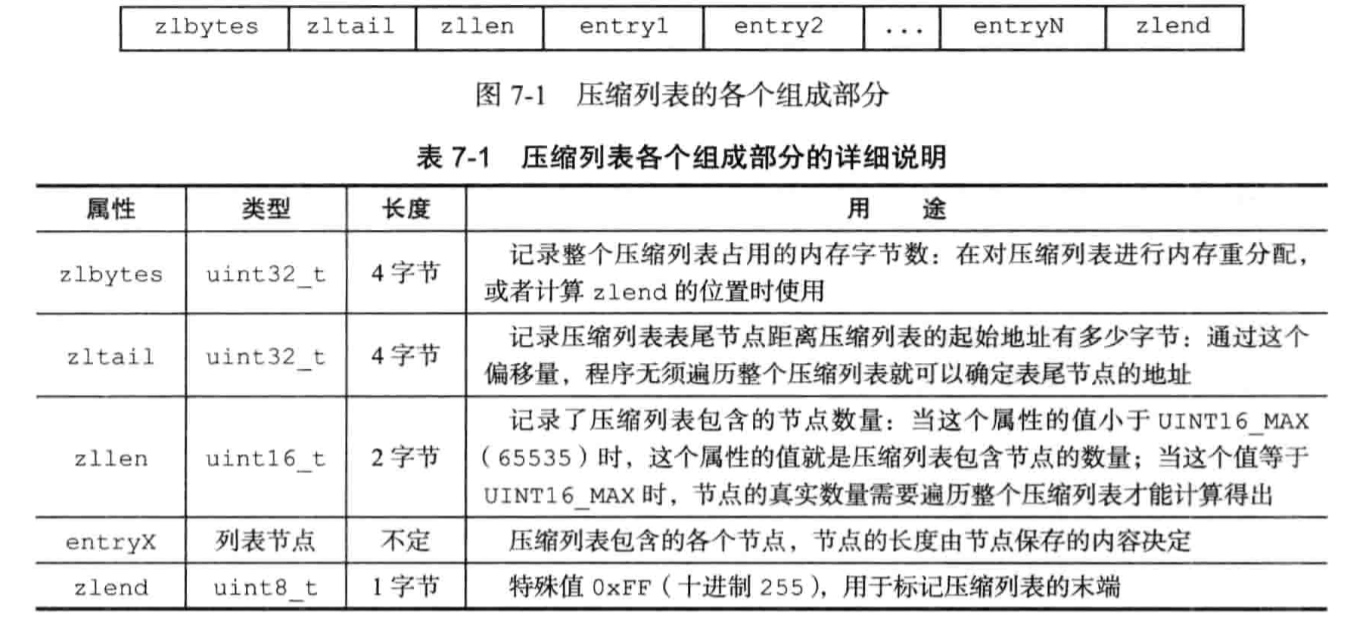

provious_entry_length记录了压缩列表前一个节点的长度,这个属性为1个字节或者五个字节,如果前一个节点长度小于254字节,则这个属性为一个字节,否则这个属性为五个字节。
如果在一个节点都为小于254字节的压缩链表中间插入一个新的大于254字节的节点A,后一个节点B的previous_entry_length就会从一个属性变为5个属性,从而导致节点B也可能超过254字节…
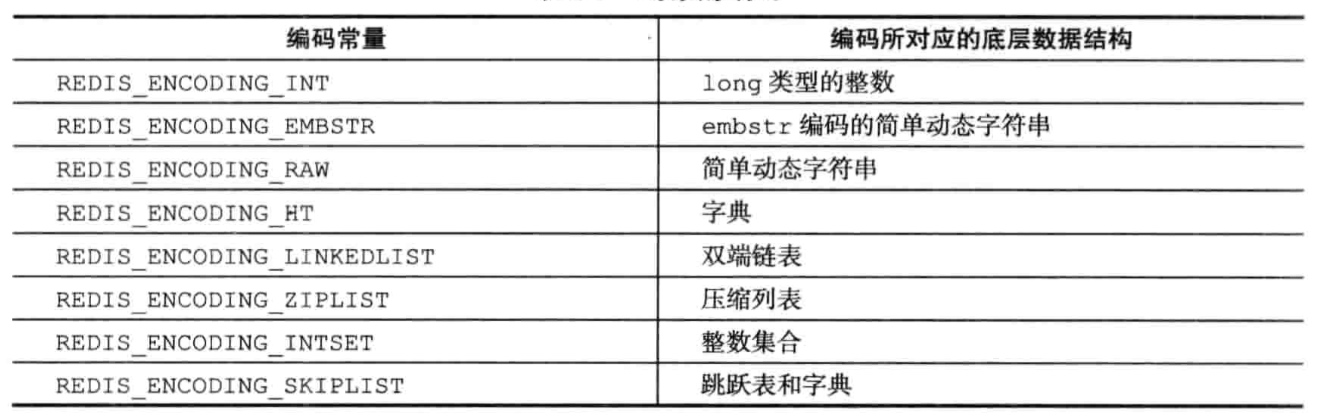
Redis没有使用上面的数据结构直接实现数据库,而是基于这些数据结构创建了一个对象系统,包括以下五种类型:
我们可以针对不同的使用场景,为对象设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率。
基于引用计数技术的内存回收机制,回收不再使用的对象,在适当条件下,让多个数据库键共享一个对象来节约内存。
SET msg “hello world”
会分表为键和值创建redisObject对象:
type: REDIS_STRING, REDIS_LIST, REDIS_HASH, REDIS_SET, REDIS_ZSET
redis> TYPE msg
string
不同类型对象的创建
SET msg “hello world” #字符串对象 string
HMSET profile name Jason age 20 career Engineer # 哈希对象hash
SADD fruits apple banana cherry # 集合对象 set
ZADD price 8.5 apple 5.0 banana 6.0 cherry # 有序集合对象 zset
查看数据库键的值对象的编码:
redis> OBJECT ENCODING msg
字符串对象REDIS_STRING的编码可以是int,raw或者embstr。
例子:
redis> SET number 10000
redis> OBJECT ENCODING number # int
redit> SET story “data structure algorithrm operation system …”
redis> OBJECT ENCODING story # raw 长度大于32个字节
redis> SET msg “hello”
redis> OBJECT ENCODING msg # embstr 长度小于等于32个字节
redis> SET pi 3.14
redis> OBJECT ENCODING pi # embstr

embstr字符串不允许修改,在执行修改命令时会先转换为raw编码。

编码:ziplist或者linkedlist
redis> RPUSH numbers 1 “a” 2
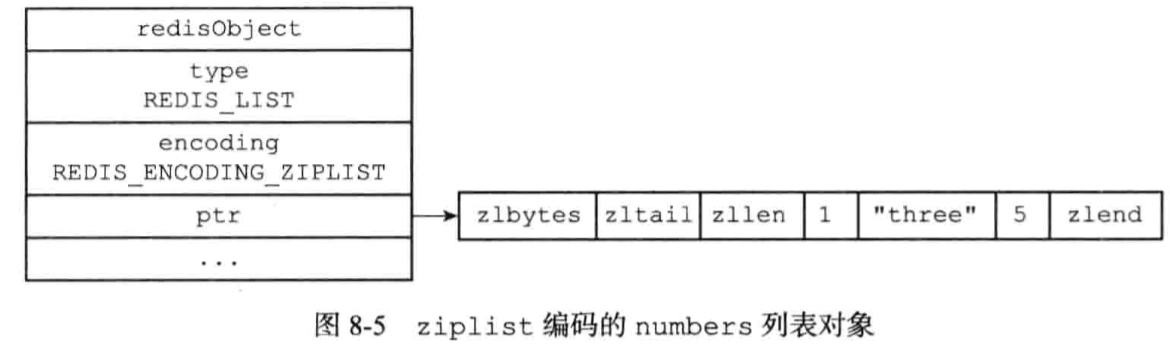
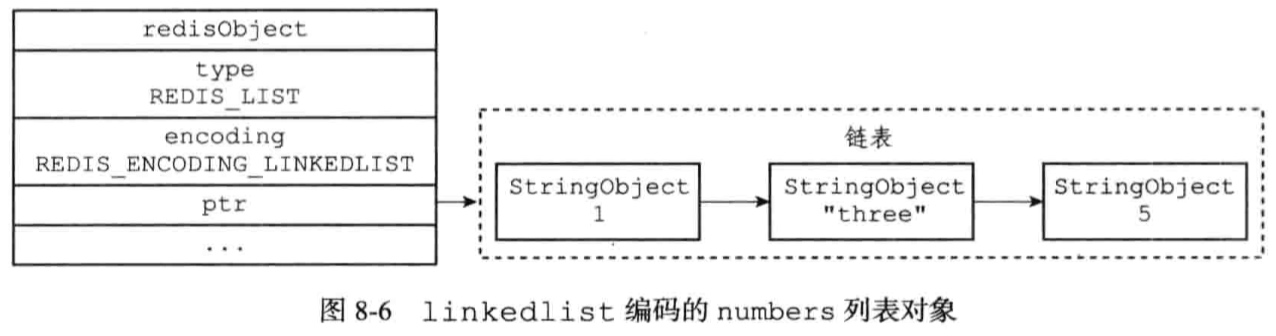
字符串对象是Redis五种类型的对象中唯一一种会被其他四中类型对象嵌套的对象。
使用ziplist编码的条件:
以上上限可修改(list-max-ziplist-value list-max-ziplist-entries)
编码:ziplist或者hashtable
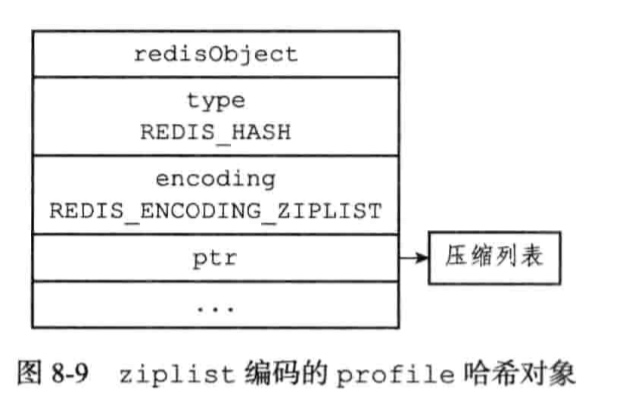

字典的键和值都是字符串对象
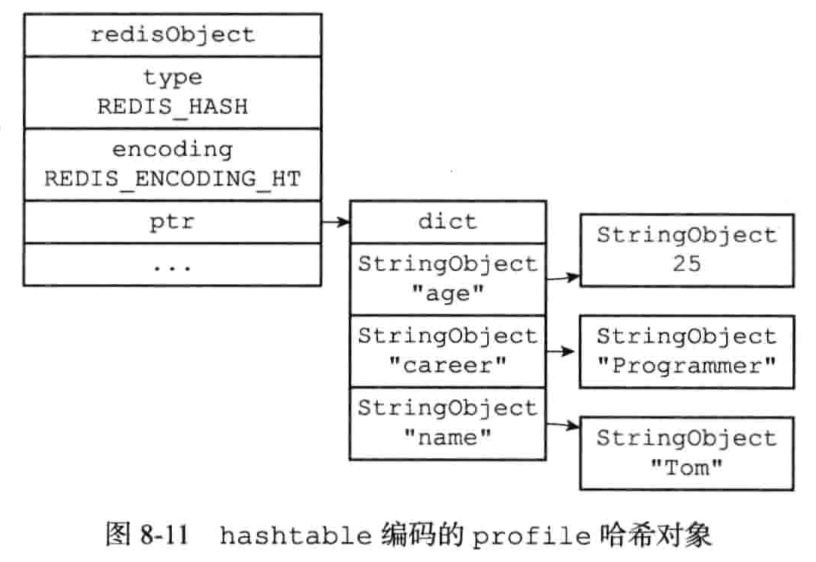
使用ziplist对象的条件:
以上上限可修改(hash-max-ziplist-value hash-max-ziplist-entries)
集合对象的编码:intset或者hashtable
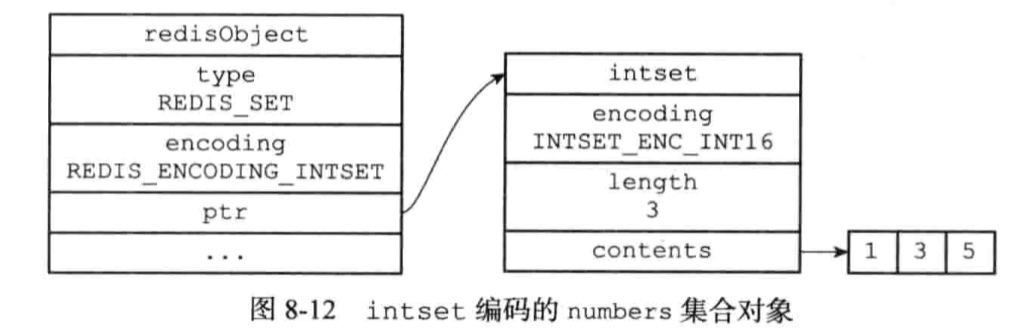
集合对象包含的所有元素都被保存在整数集合里面;
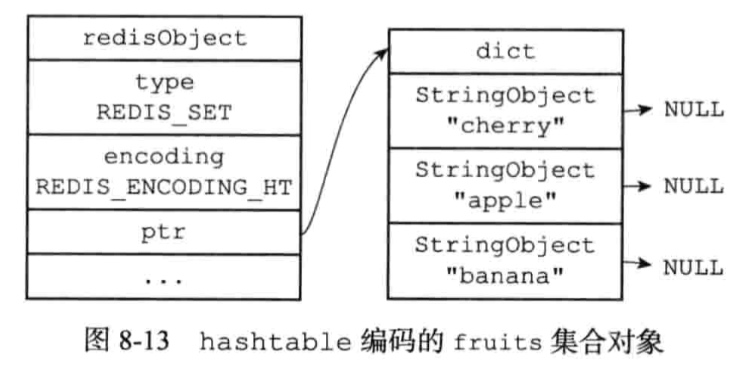
hashtable使用字典作为底层实现,字典的值全部设置为NULL。
使用intset对象的条件:
上限可以修改(set-max-intset-entries)
编码:ziplist或者skiplist
每个集合使用紧挨着的两个压缩列表节点来表示,第一个节点保存元素成员,第二个元素保存元素的分值;按分值从小到大进行排列;
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset同时包含一个字典和一个跳跃表:
1 | typedef struct zset { |
单独通过字典或者跳跃表来实现有序集合,性能都会有所下降。
字典和跳跃表会共享元素的成员和分值,所以并不会造成任何数据重复,也不会因此而浪费内存。
使用ziplist的条件:
修改参数:zset-max-ziplist-entries,zset-max-ziplist-value。
Redis用于操作键的命令可以分为两种:
字符串对象:SET,GET,APPEND,STRLEN
哈希对象:HDEL,HSET,HGET,HLEN
列表对象:RPUSH,LPOP,LINSERT,LLEN
集合对象:SADD,SPOP,SINSERT,SCARD
有序集合对象:ZADD,ZCARD,ZRANK,ZSCORE
对于第二类命令,在执行之前,需要先执行类型检查,通过redisObject结构的type属性来实现的。
每一种类型的对象,底层的编码是不一样的,执行同样的LLEN命令,底层是ziplist还是linkedlist编码,需要确保命令都可以正常运行,这就是命令的多态(包括可以对任何类型的键执行的命令)。
通过Redis系统内构建的引用计数器来实现内存回收
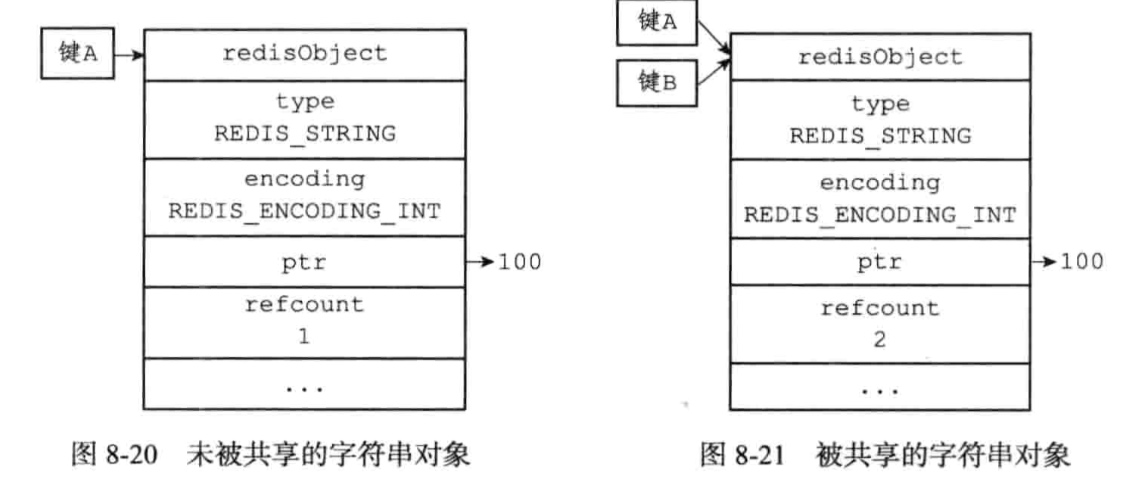
被共享的的对象,引用计数器会对应+1。
Redis在启动的时候会创建一万个字符串对象,这些字符串对象包含了从0到9999的所有整数值,通过共享对象方式使用这些值,而不是新创建对象。
修改初始化的共享对象个数:redis.h/REDIS_SHARED_INTEGERS
查看引用计数:
redis> OBJECT REFCOUNT obj
将一个共享对象设置为键的值对象时,程序会先进行检查校验想要创建的对象和目标对象是否完全一致:
收到CPU时间的限制,Redis只对包含整数值的字符串进行共享。

redisObject对象的lru属性记录了对象最后一次被命令程序访问的时间。
如果服务器打开了maxmemory选项,并且服务器用户回收内存的算法为volatile-lru或者allkeys-lru,那么服务器占用的内存数超过了maxmemory选项所设置的上限值时,空转时长较高的那部分键就会优先被服务器释放。
本文来源于《Redis设计与实现》,笔记摘要与相关问题思考。
1 | struct redisServer { |
数据库的数量由dbnum属性决定,默认情况下,Redis会创建16个数据库。
默认情况下,redis客户端的目标数据库为0号数据库,可以通过SELECT命令来切换目标数据库。
1 | typde struct redisClient { |
redis-cli客户端会在输入符旁边提示当前所使用的数据库:
redis[1] > SELECT 2
但是其他语言客户端却没有,为了避免操作错误数据库,执行Redis命令(如FLUSHDB)之前,最好先执行以下SELECT命令。
1 | typedef struct redisDb { |
添加新键
redis> SET data “2016.07.31”
redis> RPUSH list “a” “b” “c”
redis> HSET hashTable name “test”删除键
redis> DEL book更新键
redis> SET data “2016.08.01”对键取值
redis> GET str
redis> LRANGE list 0 -1
redis> EXPIRE KEY 5 // 缓存5秒
redis> EXPIREAT key 1377252100
返回距离这个键被服务器自动删除还有多长时间。
redisDb中的expires字典保存了所有键的过期时间。
在过期字典中查找给定的键,并解除键和值在过期字典的关联。
定时删除
会对服务器的响应时间和吞吐量造成影响。
惰性删除
如果一个过期的键一直没被访问到,那么永远也不会被删除。
定期删除
每个一段时间进行一次删除操作,限制删除操作执行的时长和频率减少删除操作对CPU时间的影响。
Redis使用惰性和定期删除两种策略。
执行SAVE或者BGSAVE命令创建一个新的RDB文件时,程序会对键进行检查,已过期的键不会被保存到新创建的RDB文件中。
载入的过程中,如果是主服务器,只会载入未过期的键;如果是从服务器模式,所有键都会被载入,不过在进行数据同步的时候,从服务器的数据库就会被清空,所以过期键对RDB文件的从服务器不会造成影响。
如果以AOF模式持久化数据,当过期键被惰性或者定期删除的时候,会向AOF文件追加一条DEL命令。
主服务器删除一个过期键之后,会显示地向所有从服务器发送一个DEL命令。
从服务器存在过期的键,客户端从该从服务器继续获取该键,仍可以获取到;但是从主服务器获取,主服务器发现该键已过期,向客户端返回空回复,并向从服务器发送DEL message命令。
获取0号数据库中针对message键执行的所有命令:
redis> SUBSCRIBE _ keyspace@0 :message
获取0号数据库中所有执行DEL命令的键:
redis> SUBSCRIBE keyevent@0 _:del
服务器配置的notify-keyspace-events选项决定了服务器所发送通知的类型
void notifyKeyspaceEvent(int type, char event robj key, int dbid)
程序会根据type这个值来判断通知是否就是服务器配置notify-keyspace-events选项所选定的通知类型,如果是。
例如:notifyKeyspaceEvent(REDIS_NOTIFY_SET, “sadd”, c->argv[1], c->db->id);
当SADD命令向集合成功的添加元素,命令就会发送。
发送通知的实现

生成RDB文件的命令:
实际由rdb.c/rdbSave函数完成
RDB文件的载入是在服务器启动时自动执行的,期间服务器一直会处于阻塞状态。Redis没有专门用于载入RDB文件的命令。
如果开启了AOF持久化功能,服务器会优先使用AOF文件还原数据;
AOF持久化功能处于关闭的情况下,服务器使用RDB文件来还原数据库状态;
相关函数:rdb.c/rdbLoad;
SAVE命令执行会阻塞服务器,客户端所有命令都会被拒绝;BGSAVE命令有子进程执行,创建RDB文件过程中仍然可以继续处理客户端命令请求,但是此时,客户端发送的SAVE命令会被服务器拒绝,避免父进程和子进程同事执行两个rdbSave调用,防止产生竞争条件。同事,客户端再发送BGSAVE命令也会被拒绝。BGREWRITEAOFhe BGSAVE命令不能同时执行,执行BGSAVE期间发送的BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后执行。执行BGREWRITEAOF期间,BGSAVE命令会被服务器拒绝。(BGSAVE和BGREWRITEAOF虽然都是在子进程里面执行的,不能同时执行是出于服务器性能考虑的)Redis运行用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令:
save 900 1
save 300 10
save 60 10000 # 服务器在60秒内,对数据库进行了至少10000次修改,则执行BGSAVE命令
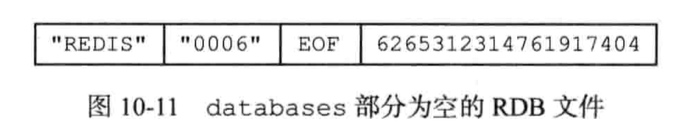
固定REDIS开头,0006是版本号,最后是文件校验和。

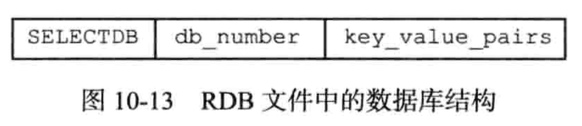
key_value_pairs保存了数据库中所有键值对数据。

可分为不带过期和带过期时间的键值对:
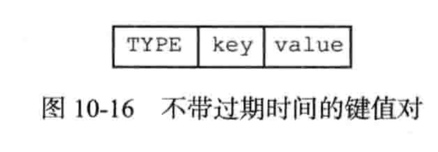
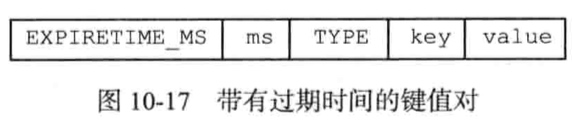
其中type表示编码类型,key是一个字符串,value因type的不同结构也会不一样。
字符串对象:如果是REDIS_ENCODING_RAW,又可根据长度是否大于20字节分为压缩和不压缩两种方式。(需要打开RDB文件压缩功能:redis.conf的rdbcompression),压缩格式如下:
列表对象:
REDIS_ENCODING_LINKEDLIST:


每一个item又是一个字符串对象。
集合对象:
REDIS_ENCODING_HT:
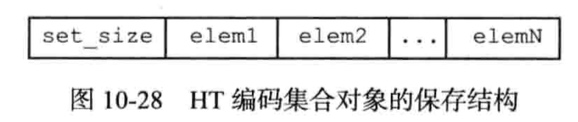
有序集合对象:
REDIS_ENCODING_SKIPLIST:

哈希表对象:
REDIS_ENCODING_HT:

ZIPLIT编码的列表、哈希表或者有序集合
将压缩列表转换成一个字符串对象,保存到RDB文件中。
可以通过od命令来分析RDB文件
redis> od -c dump.rdb
AOF即:Append Only File。
RDB通过保存数据库中的键值对来记录数据库状态的不同,AOF持久化通过保存Redis服务器所执行的命令来记录数据库状态。
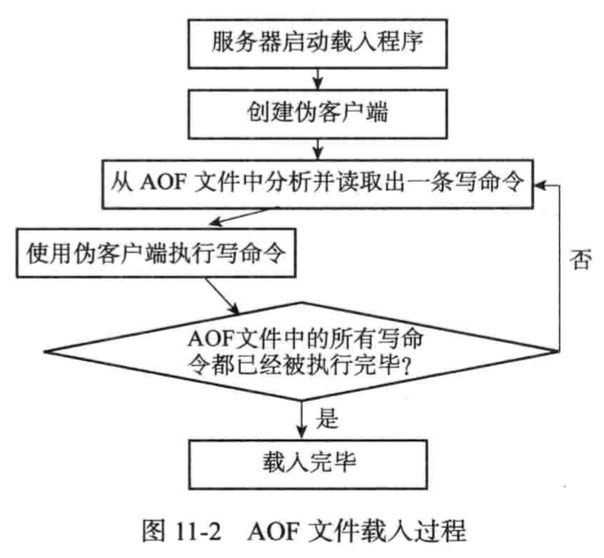
AOF持久化实现分为:命令追加(追加到aof_buf),文件写入,文件同步。
Redis在一个事件循环里,每次都做判断,根据服务器的appendfsync配置选择对应的策略来进行AOF文件的写入和同步。
为了节省AOF文件的空间,去除冗余的命令。
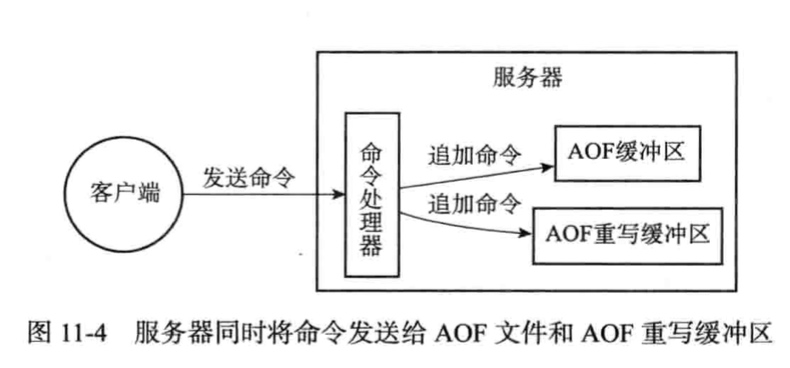
通过调用aof_rewrite函数进行重写,在子进程中进行重写,重写过程新发送的命令按如下处理:
Redis是一个事件驱动程序,服务器处理文件事件和时间时间两类事件。
基于Reactor模式开发的网络事件处理器。使用IO多路复用同时监听多个套接字,根据套接字执行的任务为套接字关联不同的事件处理器。
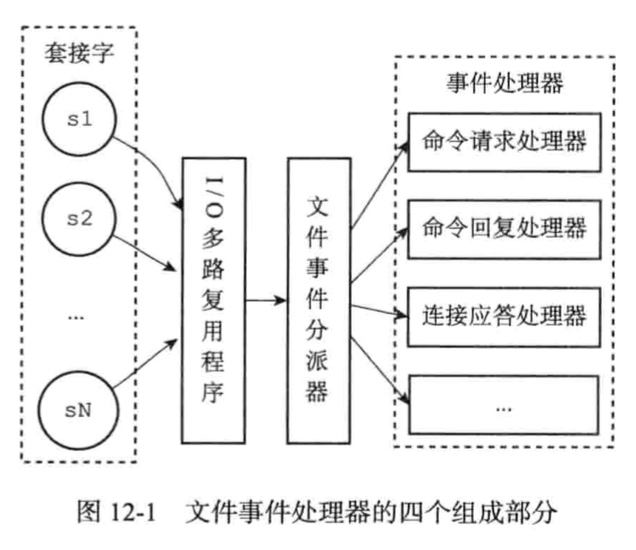
IO多路复用程序所有功能都是通过封装常见的select、epoll、evport、kqueue这些I/O多路复用函数库来实现的。
连接应答处理器:对连接服务器监听套接字的客户端进行应答,Redis服务器进行初始化的时候,程序会将这个连接应答处理器和服务器监听套接字的AE_READABLE事件关联起来,引发连接应答处理器执行,并执行相应的套接字应答操作。
命令请求处理器:从套接字中读入客户端发送的命令请求内容,当一个客户端通过连接应答处理器成功连接到服务器之后,服务器会将客户端套接字的AE_READABLE事件和命令请求处理器关联起来,当客户端向服务器发送命令请求的时候,套接字就会产生AE_READABLE事件,引发命令请求处理器执行,并执行相应的套接字读入操作。
命令回复处理器:当服务器有命令回复需要传送给客户端的时候,服务器会将客户端套接字的AE_WRITEABLE事件和命令回复处理器关联起来,当客户端准备好接受服务器传回的命令回复时,就会产生AE_WRITEABLE事件,引发命令回复处理器执行,并执行相应的套接字写入操作。
某些场合需要把全量关系写到内存中,不然还是会存储缓存找不到,再次去磁盘数据库查找的情况,这种时候干脆直接用Redis作为数据存储方案了。
先弄清楚两点:
类似微博,这种社交应用,数据是不要求100%不丢失的,所以可以很好的利用缓存来解决高并发的处理问题;
而如果涉及到资金交易,像金融系统或者是电商网站的核心交易模块,数据是不运行有误的,这部分数据,如果从缓存上来考虑兼容高并发,是无法做到安全的,退一步的做法,应该是使用数据库的Sharding方式和流量漏洞过滤的方式来应对高并发的场景。而非核心交易的模块,如购物车,还未确认的订单,可以考虑系统的对错误的容忍度恰当的放到缓存里面,然后通过一定的策略做其他的业务处理,如持久化数据做MapReduce和分析作业。
缓存的设计有哪些套路呢,酷客里面的缓存更新的套路说了常用的设计思路。单靠缓存来解决高并发的数据读写又想做数据的强一致性和可靠性,是没有这样的银弹的,这个时候需要转换一下思路。
MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error
redis.conf
dbfilename dump.rdb
dir ./
查看文件写入权限,以及磁盘是否已满。
info
stop-writes-on-bgsave-error yes
nexus Return code is: 401, ReasonPhrase: Unauthorized.
查看是否配置了认证
1 | <servers> |
一个数据库:
user_center
里面有三个表:
t_user:用户信息表
t_order:订单表
t_user_stat:用户数据统计表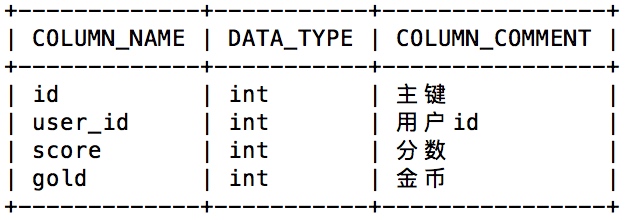
现在要求:用户每创建一个订单,不管成功与否,都给用户奖励一个金币。
sql语句如下:
1 | INSERT INTO `t_order` (`user_id`,`order_id`,`status`,`amount`) |
为了让这条sql语句在一个事务里面执行,我们需要开启事务,在事务里面处理,结果就如下:
1 | set autocommit=0; |
以下是Spring的事务管理器的相关类:
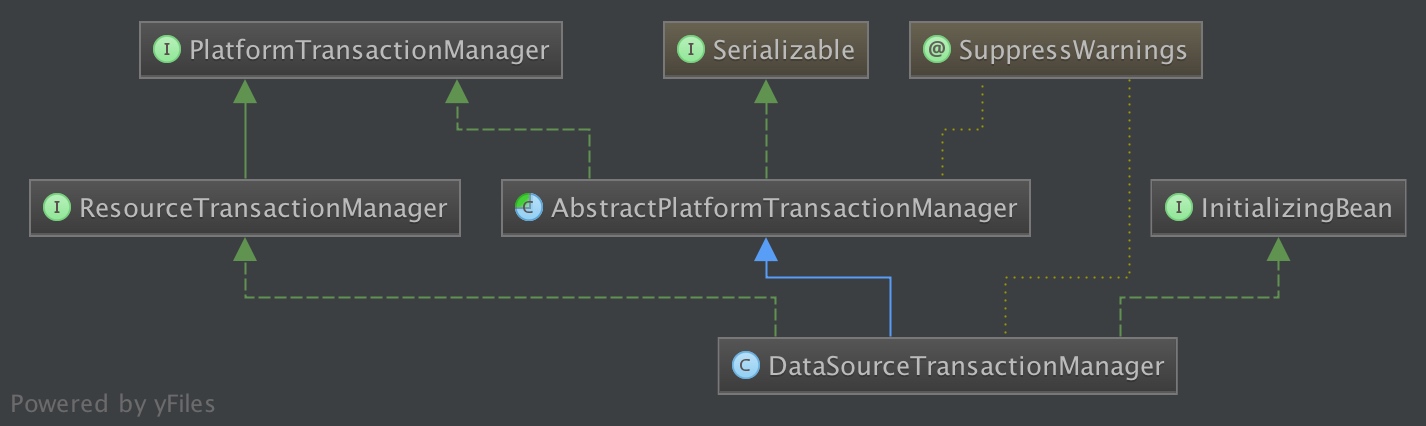
事务的提交、回滚等操作是通过直接调用数据库连接Connection的提交和回滚方法实现的。
而Spring提供的HibernateTransactionManager,真正执行提交、回滚等事务操作的还是Hibernate Transaction事务对象,Spring将其做了通用封装,更加方便使用:
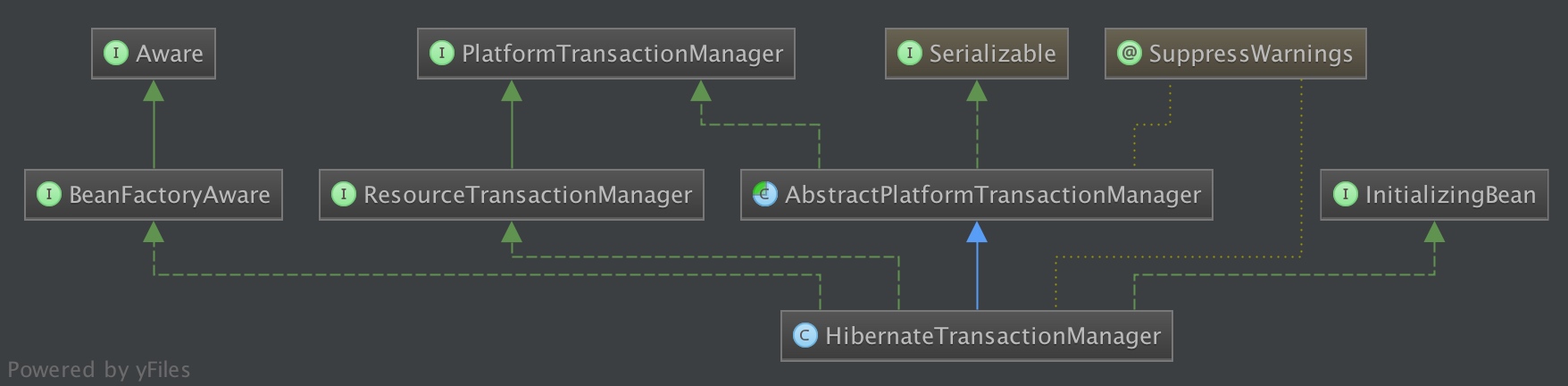
阅读延伸:
Java事务的类型有三种:JDBC事务、JTA(Java Transaction API)事务、容器事务。
目前,项目中集成了MyBatis和Hibernate。
1 | <bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager"> |
Mybatis和JdbcTemplate的事务也是受spring管控的,他们都是用的JDBC的事务,所以只有他们的数据源是一样的就可以让spring来管理事务。
如果直接在项目中使用DataSourceTransactionManager的话,对于Hibernate,会出现拿不到session的异常,对于同时集成MyBatis和Hibernate的项目,最佳实践还是使用HibernateTransactionManager。
问题:对于读写分离的系统,如何设置事务呢?
在应用层的解决方案,通过spring动态数据源和AOP来解决数据库的读写分离。
方案1:当只有读操作的时候,直接操作读库(从库);当在写事务(即写主库)中读时,也是读主库(即参与到主库操作),这样的优势是可以防止写完后可能读不到刚才写的数据;
此方案其实是使用事务传播行为为:SUPPORTS解决的。
方案2:当只有读操作的时候,直接操作读库(从库)当在写事务(即写主库)中读时,强制走从库,即先暂停写事务,开启读(读从库),然后恢复写事务。
此方案其实是使用事务传播行为为:NOT_SUPPORTS解决的。
数据库隔离级别
| 时间 | 事务一 | 事务二 |
|---|---|---|
| 1 | START TRANSACTION; | |
| 2 | INSERT INTO t_order (user_id,order_id,status,amount) VALUES (1, “2016062701837x9d”, 0, 10000); |
START TRANSACTION; |
| 3 | UPDATE t_user_stat SET gold = gold + 1 WHERE user_id = 1; |
INSERT INTO t_order (user_id,order_id,status,amount) VALUES (1, “2016062701837x9d”, 0, 10000); |
| 4 | COMMIT; | 等待获取Update行锁 |
| 5 | - | UPDATE t_user_stat SET gold = gold + 1 WHERE user_id = 1; |
| 6 | - | COMMIT; |
为了方式行锁阻塞了另一个事务的处理,事务应该尽量的小,不要做过多的事情;更不要发送HTTP请求,不然,遇到高并发的请求过来,很快把数据库连接耗尽。
事务隔离级别及其特性
怎么选择事务隔离级别
PROPAGATION_REQUIRED(加入已有事务)
尝试加入已经存在的事务中,如果没有则开启一个新的事务。
RROPAGATION_REQUIRES_NEW(独立事务)
挂起当前存在的事务,并开启一个全新的事务,新事务与已存在的事务之间彼此没有关系。
PROPAGATION_NESTED(嵌套事务)
在当前事务上开启一个子事务(Savepoint),如果递交主事务。那么连同子事务一同递交。如果递交子事务则保存点之前的所有事务都会被递交。
PROPAGATION_SUPPORTS(跟随环境)
是指 Spring 容器中如果当前没有事务存在,就以非事务方式执行;如果有,就使用当前事务。
PROPAGATION_NOT_SUPPORTED(非事务方式)
是指如果存在事务则将这个事务挂起,并使用新的数据库连接。新的数据库连接不使用事务。
PROPAGATION_NEVER(排除事务)
当存在事务时抛出异常,否则就已非事务方式运行。
PROPAGATION_MANDATORY(需要事务)
如果不存在事务就抛出异常,否则就已事务方式运行。
从MySQL的事务模型说起
请问下面的MySQL SQL,假设like_num初始值为30,执行结果会怎样?
1 | START TRANSACTION; |
嵌入式事务模型:在嵌入式事务模型中,如果你开启了一个事务,并且想在当前事务下继续开启一个新的事务,第一个事务依旧会保持正常的开启状态,也就是说,第二个事务会嵌套在第一个事务里面;平面事务模型:而在平面式事务中,是不允许事务嵌套的,如果开启了一个事务之后,继续开启另一个事务,会自动先提交第一个事务。
MySQL使用了平面事务模型:嵌套的事务是不允许的,在连续开启第二个事务的时候,第一个事务自动提交了。
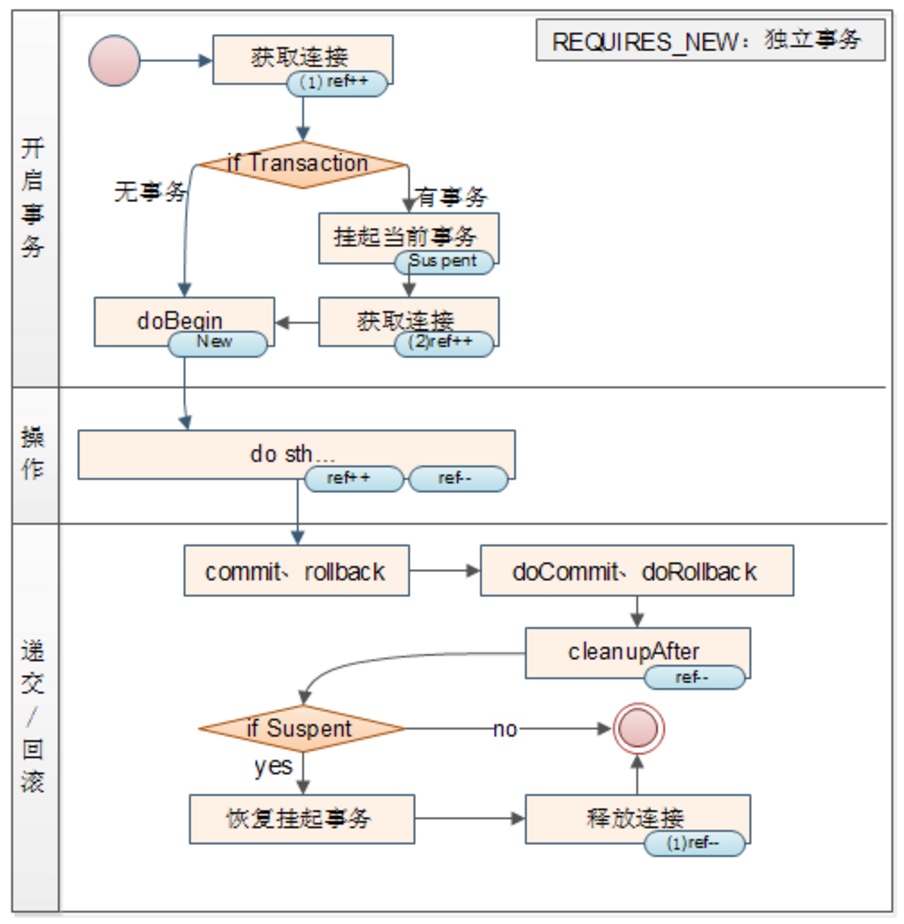
JTA(Java Transaction API)里面就提供了suspend()和resume()的接口,用于实现这种事务使用场景:
javax.transaction.TransactionManger.suspend()
javax.transaction.TransactionManger.resume(Transation)
PROPAGATION_REQUIRED,这个会有什么问题1 | ("userService") |
Spring的默认传播特性,如果通过在Class文件头部添加注解的方式,默认都使用这个事务隔离级别,很容易写出事务执行时间比较长的代码,不容易控制。
RROPAGATION_REQUIRES_NEW1 | public void addComment(){ |
不管saveLogInfo(logInfo)后续执行是否成功,saveLogInfo都要持久化到数据库,则saveLogInfo()方法需要使用RROPAGATION_REQUIRES_NEW隔离级别
PROPAGATION_NESTED1 | public void methodA() { |
如果希望不管serviceB.methodB()方法是否执行成功还是抛出异常,都希望不影响外部调用方法数据改动的提交,则可以考虑在methodB()方法使用PROPAGATION_NESTED。
常见的场景有:
PROPAGATION_SUPPORTSPROPAGATION_NOT_SUPPORTEDPROPAGATION_NEVER和PROPAGATION_MANDATORY是用来做什么的这里就是分布式事务的问题了,传统的解决方法有二阶段事务提交
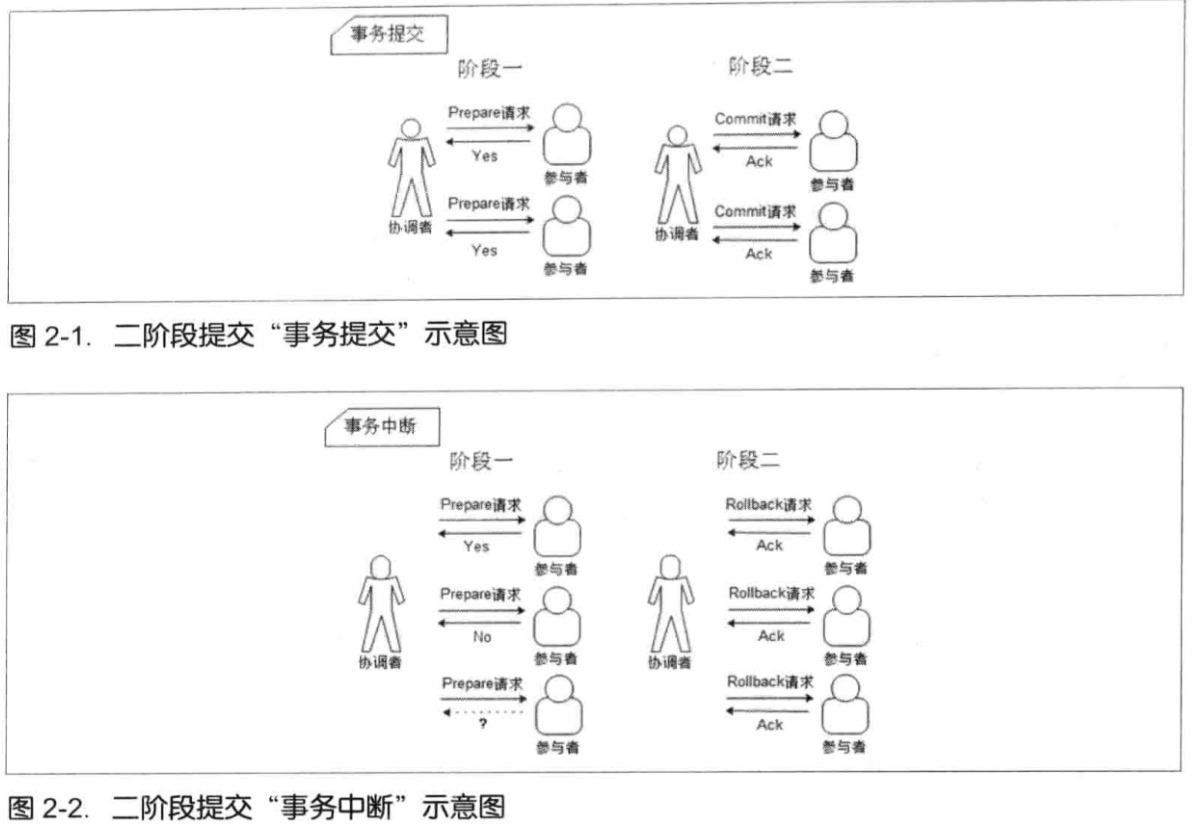
优化,三阶段事务提交
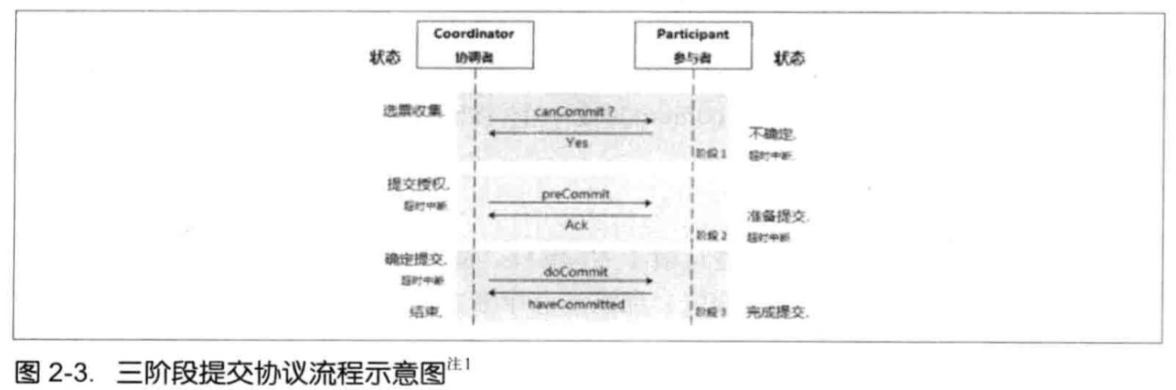
但是,这两种方式都是效率比较低的,在互联网高并发的应用下不具有实用性,CAP定理告诉我们,无法同时满足,放弃任何一个都会带来其他的隐患,而BASE理论则给了我们很好的解决方法,只要能够保持数据的最终一致性,就可以保证系统正确的运行了。
目前主流的处理方式是通过消息补偿机制实现数据的最终一致性。
举个例子,我们的系统跟易宝系统打交道的场景。
交易系统与钱包系统怎么保证两个系统的数据一致性
dubbo幂等性;
秒杀系统数据库减压方法;
节流:仅让能成功抢购到商品的流量(可以有一定余量)进入我们的系统。
削峰:将进入系统的瞬时高流量拉平,使得系统可以在自己处理能力范围内,将所有抢购的请求处理完毕。
异步处理:
可用性:
用户体验:
分布式锁(乐观锁)
如何确保消息不丢失,zk选举原理及其数据修复。
在进行功能设计的时候,必须考虑上事务处理:
《Spring技术内幕》学习笔记16——Spring具体事务处理器的实现
Spring技术内幕
对于一些其他系统依赖的Jar包,例如 service-api, app-core 之类的,假设当前版本如下:
1 | <dependency> |
如果我们要对这个Jar包进行改造,最好是新开一个特性分支,避免影响原有其他项目组正则调试的项目。
如果需要在原有分支上改动,则需要把该分支最新的代码打成Jar包推送到Maven私服,推送完之后再升级版本号为1.0.2进行后续的调整。这样有如下作用:
1.0.1版本的Jar包即是最新的,不影响到该版本下功能的开发;1.0.1最新的代码deploy到Maven,确保了不会用到不是最新的1.0.1版本的代码;service-api的项目,由于项目版本号升级为了1.0.2,此时,如果项目配置不变,会自动去Maven私服上拉取1.0.1的Jar包,不影响原有功能。不过,最好的方式还是在新特性分支上进行修改,修改完确定之后,视改动大小看需不需要升级版本号,然后把代码合并回master(如果升级了版本号,在合并会master之前请记得把原来master分支的代码重新打包deploy一遍,确保maven私服上面的jar包是最新的),提交到master分支的代码记得打包deploy到Maven私服,后续改动基于最新的版本号继续进行开发。