使用事务
一个数据库:
user_center
里面有三个表:
t_user:用户信息表
t_order:订单表
t_user_stat:用户数据统计表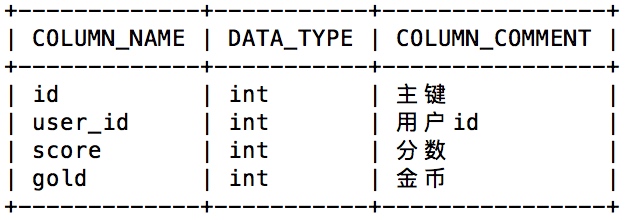
现在要求:用户每创建一个订单,不管成功与否,都给用户奖励一个金币。
sql语句如下:
1 | INSERT INTO `t_order` (`user_id`,`order_id`,`status`,`amount`) |
为了让这条sql语句在一个事务里面执行,我们需要开启事务,在事务里面处理,结果就如下:
1 | set autocommit=0; |
Spring事务管理
以下是Spring的事务管理器的相关类:
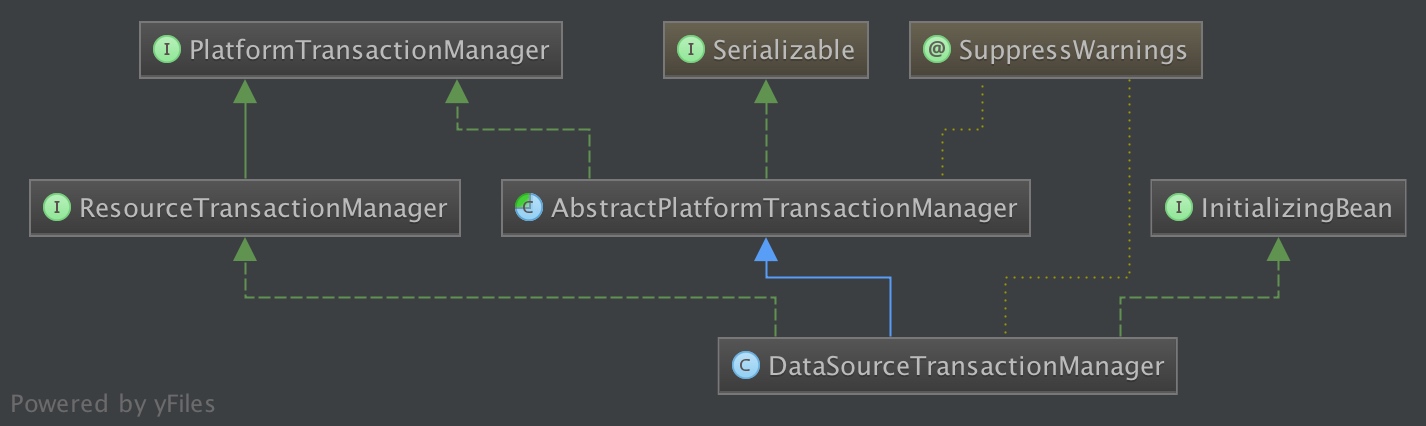
事务的提交、回滚等操作是通过直接调用数据库连接Connection的提交和回滚方法实现的。
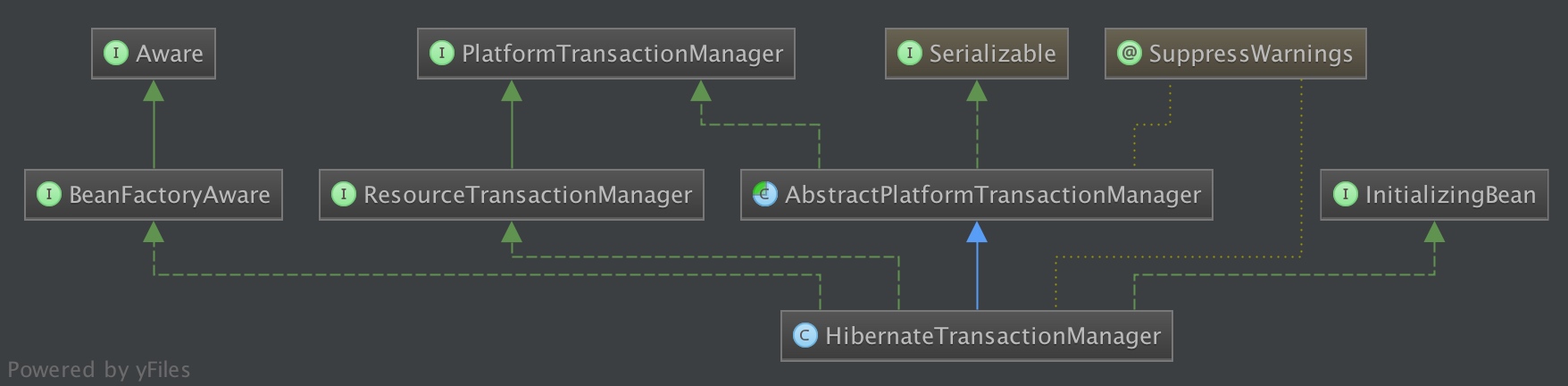
而Spring提供的HibernateTransactionManager,真正执行提交、回滚等事务操作的还是Hibernate Transaction事务对象,Spring将其做了通用封装,更加方便使用:
阅读延伸:
Java事务的类型有三种:JDBC事务、JTA(Java Transaction API)事务、容器事务。
项目中的事务配置
目前,项目中集成了MyBatis和Hibernate。
1 | <bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager"> |
Mybatis和JdbcTemplate的事务也是受spring管控的,他们都是用的JDBC的事务,所以只有他们的数据源是一样的就可以让spring来管理事务。
如果直接在项目中使用DataSourceTransactionManager的话,对于Hibernate,会出现拿不到session的异常,对于同时集成MyBatis和Hibernate的项目,最佳实践还是使用HibernateTransactionManager。
问题:对于读写分离的系统,如何设置事务呢?
在应用层的解决方案,通过spring动态数据源和AOP来解决数据库的读写分离。
方案1:当只有读操作的时候,直接操作读库(从库);当在写事务(即写主库)中读时,也是读主库(即参与到主库操作),这样的优势是可以防止写完后可能读不到刚才写的数据;
此方案其实是使用事务传播行为为:SUPPORTS解决的。方案2:当只有读操作的时候,直接操作读库(从库)当在写事务(即写主库)中读时,强制走从库,即先暂停写事务,开启读(读从库),然后恢复写事务。
此方案其实是使用事务传播行为为:NOT_SUPPORTS解决的。
两个线程并发执行事务会怎样呢
数据库隔离级别
| 时间 | 事务一 | 事务二 |
|---|---|---|
| 1 | START TRANSACTION; | |
| 2 | INSERT INTO t_order (user_id,order_id,status,amount) VALUES (1, “2016062701837x9d”, 0, 10000); |
START TRANSACTION; |
| 3 | UPDATE t_user_stat SET gold = gold + 1 WHERE user_id = 1; |
INSERT INTO t_order (user_id,order_id,status,amount) VALUES (1, “2016062701837x9d”, 0, 10000); |
| 4 | COMMIT; | 等待获取Update行锁 |
| 5 | - | UPDATE t_user_stat SET gold = gold + 1 WHERE user_id = 1; |
| 6 | - | COMMIT; |
为了方式行锁阻塞了另一个事务的处理,事务应该尽量的小,不要做过多的事情;更不要发送HTTP请求,不然,遇到高并发的请求过来,很快把数据库连接耗尽。
事务特性
事务隔离级别及其特性
怎么选择事务隔离级别
Spring的传播特性
PROPAGATION_REQUIRED(加入已有事务)
尝试加入已经存在的事务中,如果没有则开启一个新的事务。RROPAGATION_REQUIRES_NEW(独立事务)
挂起当前存在的事务,并开启一个全新的事务,新事务与已存在的事务之间彼此没有关系。PROPAGATION_NESTED(嵌套事务)
在当前事务上开启一个子事务(Savepoint),如果递交主事务。那么连同子事务一同递交。如果递交子事务则保存点之前的所有事务都会被递交。PROPAGATION_SUPPORTS(跟随环境)
是指 Spring 容器中如果当前没有事务存在,就以非事务方式执行;如果有,就使用当前事务。PROPAGATION_NOT_SUPPORTED(非事务方式)
是指如果存在事务则将这个事务挂起,并使用新的数据库连接。新的数据库连接不使用事务。PROPAGATION_NEVER(排除事务)
当存在事务时抛出异常,否则就已非事务方式运行。PROPAGATION_MANDATORY(需要事务)
如果不存在事务就抛出异常,否则就已事务方式运行。
PROPAGATION_REQUIRED_NEW 实现原理?
从MySQL的事务模型说起
问题
请问下面的MySQL SQL,假设like_num初始值为30,执行结果会怎样?
1 | START TRANSACTION; |
嵌入式事务模型:在嵌入式事务模型中,如果你开启了一个事务,并且想在当前事务下继续开启一个新的事务,第一个事务依旧会保持正常的开启状态,也就是说,第二个事务会嵌套在第一个事务里面;平面事务模型:而在平面式事务中,是不允许事务嵌套的,如果开启了一个事务之后,继续开启另一个事务,会自动先提交第一个事务。MySQL使用了平面事务模型:嵌套的事务是不允许的,在连续开启第二个事务的时候,第一个事务自动提交了。
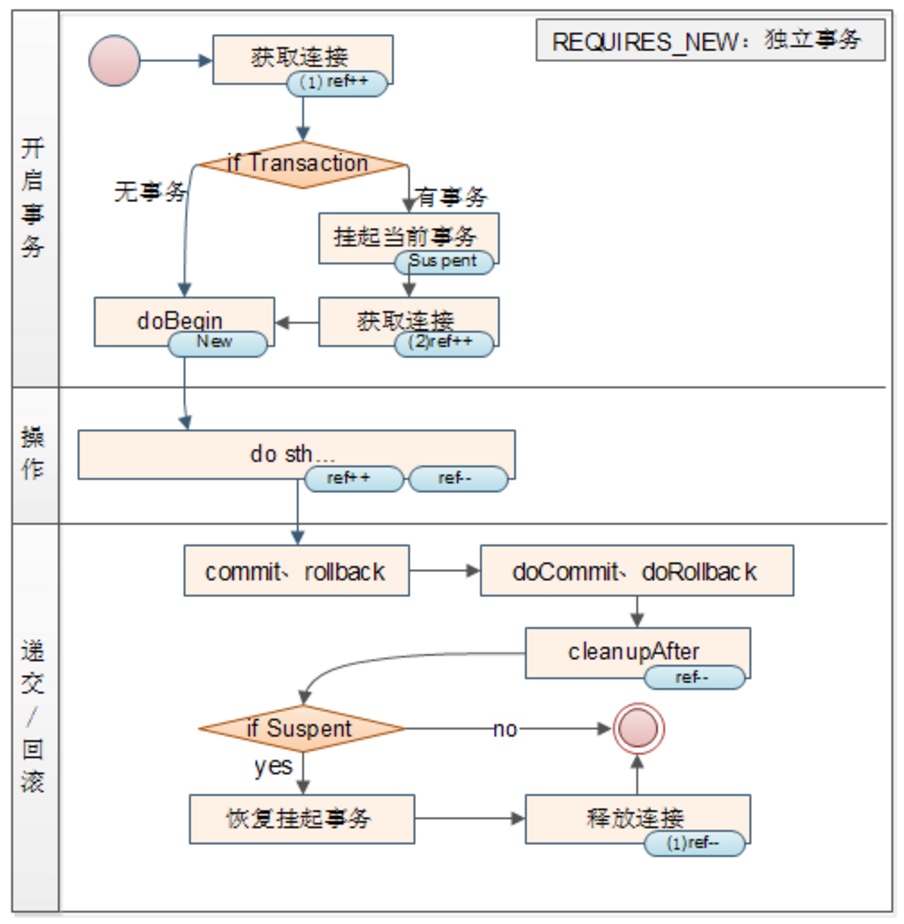
JTA(Java Transaction API)里面就提供了suspend()和resume()的接口,用于实现这种事务使用场景:
javax.transaction.TransactionManger.suspend()
javax.transaction.TransactionManger.resume(Transation)
什么时候应该使用PROPAGATION_REQUIRED,这个会有什么问题
1 | ("userService") |
Spring的默认传播特性,如果通过在Class文件头部添加注解的方式,默认都使用这个事务隔离级别,很容易写出事务执行时间比较长的代码,不容易控制。
什么时候应该使用RROPAGATION_REQUIRES_NEW
1 | public void addComment(){ |
不管saveLogInfo(logInfo)后续执行是否成功,saveLogInfo都要持久化到数据库,则saveLogInfo()方法需要使用RROPAGATION_REQUIRES_NEW隔离级别
什么时候应该使用PROPAGATION_NESTED
1 | public void methodA() { |
如果希望不管serviceB.methodB()方法是否执行成功还是抛出异常,都希望不影响外部调用方法数据改动的提交,则可以考虑在methodB()方法使用PROPAGATION_NESTED。
常见的场景有:
什么时候应该使用PROPAGATION_SUPPORTS
什么时候应该使用PROPAGATION_NOT_SUPPORTED
PROPAGATION_NEVER和PROPAGATION_MANDATORY是用来做什么的
跨系统如何处理事务
这里就是分布式事务的问题了,传统的解决方法有二阶段事务提交
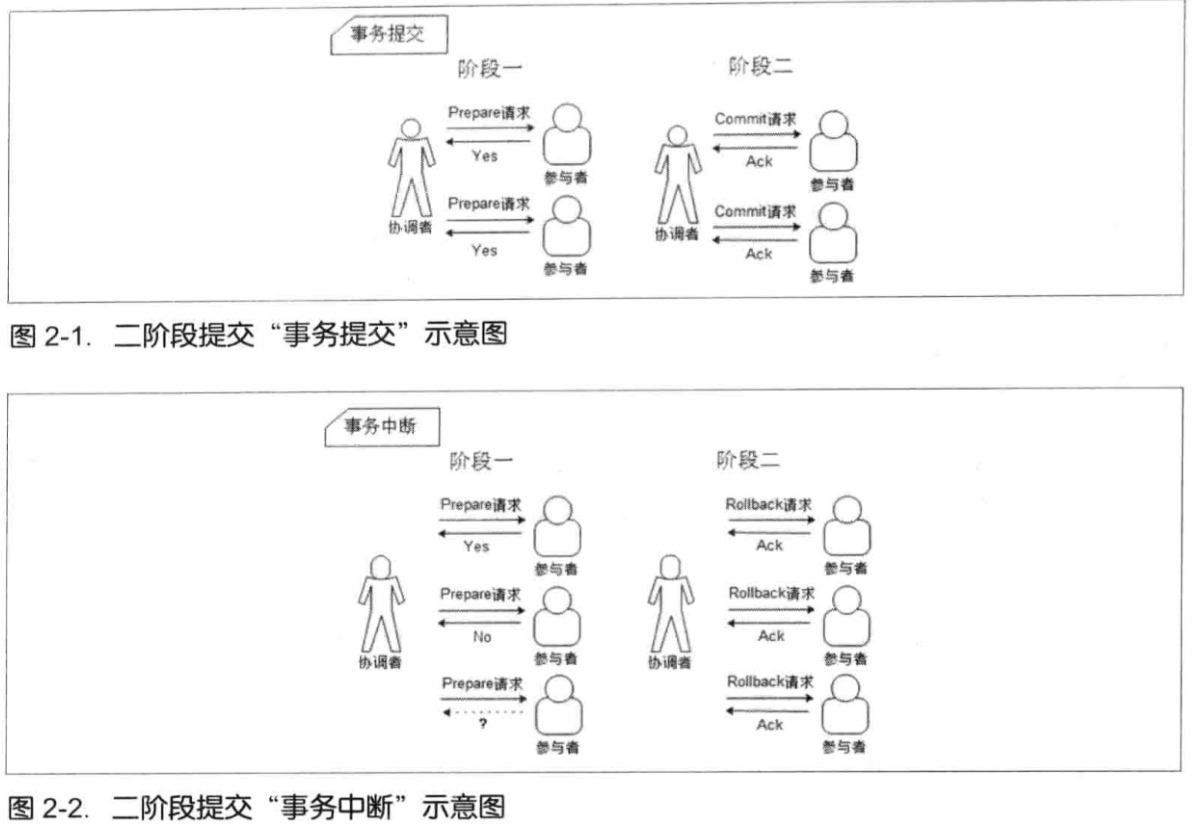
优化,三阶段事务提交
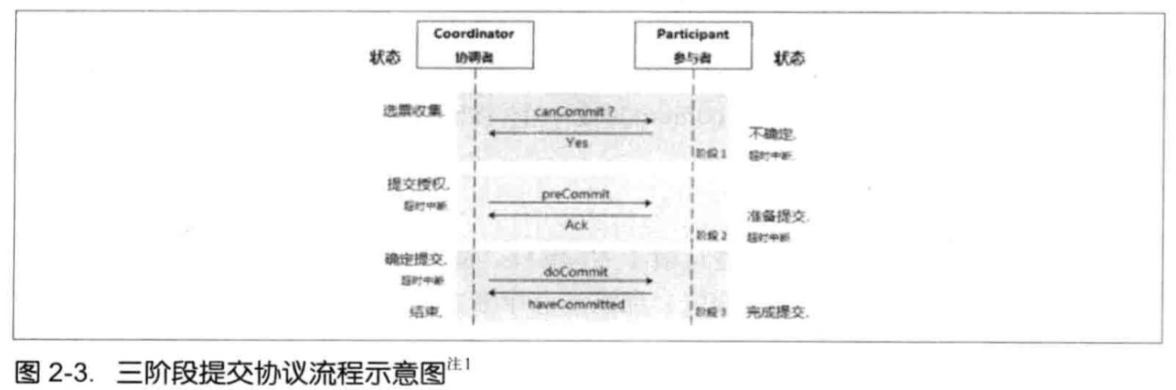
但是,这两种方式都是效率比较低的,在互联网高并发的应用下不具有实用性,CAP定理告诉我们,无法同时满足,放弃任何一个都会带来其他的隐患,而BASE理论则给了我们很好的解决方法,只要能够保持数据的最终一致性,就可以保证系统正确的运行了。
目前主流的处理方式是通过消息补偿机制实现数据的最终一致性。
举个例子,我们的系统跟易宝系统打交道的场景。
交易系统与钱包系统怎么保证两个系统的数据一致性
dubbo幂等性;
如何处理高并发情况下具有竞争关系的数据库资源
秒杀系统数据库减压方法;
节流:仅让能成功抢购到商品的流量(可以有一定余量)进入我们的系统。
削峰:将进入系统的瞬时高流量拉平,使得系统可以在自己处理能力范围内,将所有抢购的请求处理完毕。
异步处理:
可用性:
用户体验:
分布式锁(乐观锁)
如何确保消息不丢失,zk选举原理及其数据修复。
总结
在进行功能设计的时候,必须考虑上事务处理:
- 让事务尽可能小;
- 一般程序里面都会存在一个Service方法调用另一个Service方法的场景,请仔细考虑每一个方法应该设置的传播特性;
- 对于高并发场景下具有竞争关系的数据(如标的表的剩余金额,每个用户购买都会尝试对该进行扣减操作),请根据并发量大小适当做一些节流工作(乐观锁,队列控制同时创建数据库的连接数);
- 对于分布式事务,请确保每个子系统自己的事务处理正确;对于需要协调的,引入消息补偿机制实现数据的最终一致性;
- 对于与第三方系统调用,请实现幂等性;
《Spring技术内幕》学习笔记16——Spring具体事务处理器的实现
Spring技术内幕