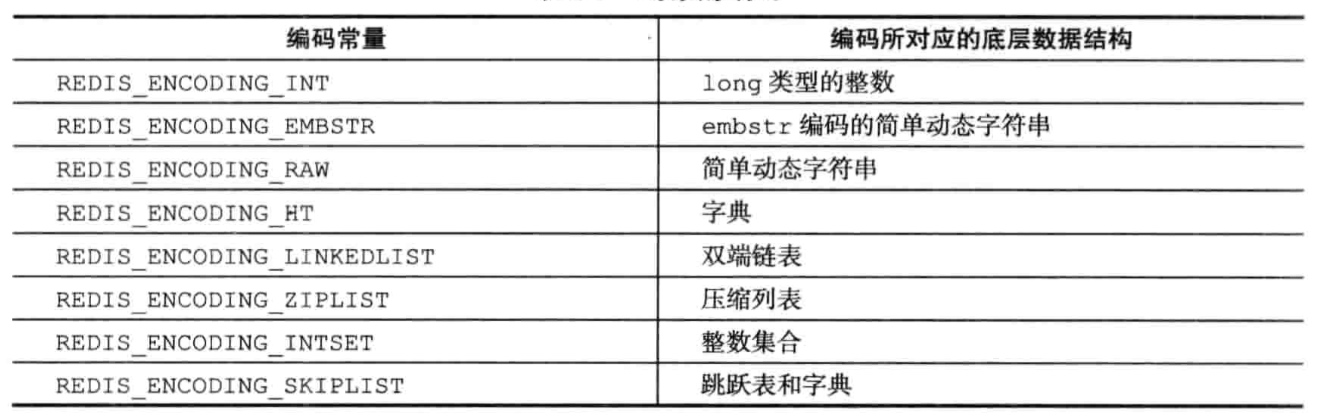
1、简单动态字符串
1.1、SDS与C字符串的不同之处,为什么Redis要使用SDS,用在了什么地方?
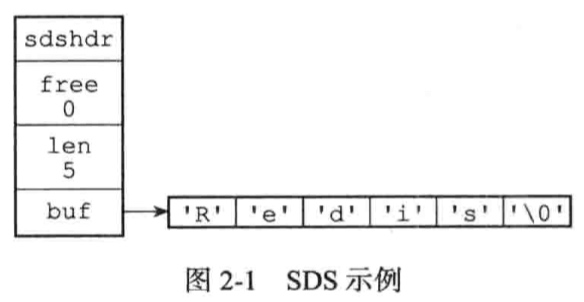
不同之处:
- C中的字符串获取字符串长度复杂度为O(N),SDS的复杂度为O(1);
- SDS杜绝缓冲区溢出,修改SDS时,API会先检查SDS空间是否满足修改所需要求,不满足则扩充至需要大小;
- SDS减少修改字符串时带来的内存重分配次数
空间预分配和惰性空间释放两种优化策略:修改后SDS小于1m,则不够时分配多一倍空间,如果多余1m,不够时则分配多1m空间 - 二进制安全:所有SDS API都会以处理二进制的方式来处理SDS存放在buf数组里的数据;
- 兼容部分C字符串函数
用于:
- 保存数据库中的字符串值
- 用作缓冲区(AOF缓冲区)
1.2、常用的SDS API有哪些
2、链表
2.1、用于
列表键,发布与订阅,慢查询,监视器等功能也用到了链表;
2.2、结构

2.3、Redis链表特性
- 双端
- 无环
- 带表头指针和表尾指针
- 带链表长度计数器
- 多态,可以存储
不同类型的值
2.4、链表和链表节点的API
3、字典
3.1、用于?
Redis数据库,对数据库的增删改查操作也是构建在对字典的操作之上的。字典还是哈希键的底层实现之一
3.2、底层实现?
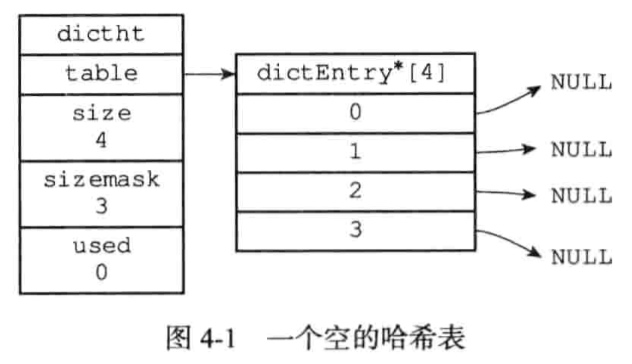
Redis使用Hash表作为底层实现
Hash表结构
值可以是一个指针,或者是一个unit64_t整数,或者int64_t整数
字典结构
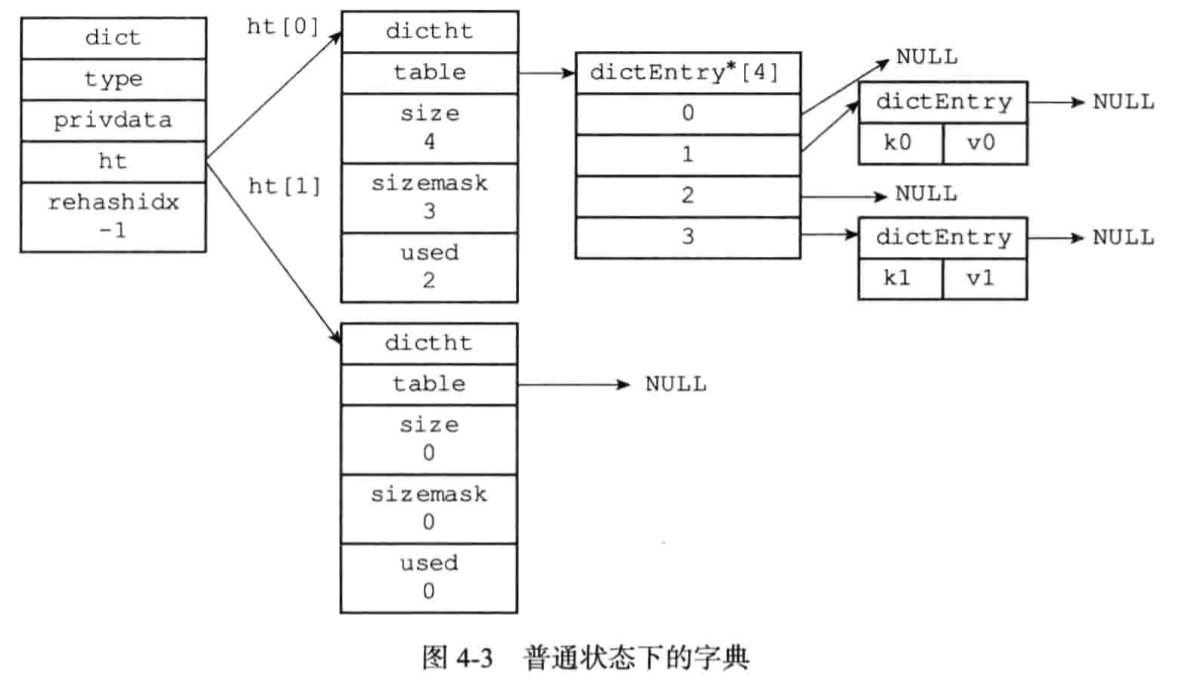
ht[1]只会在对ht[0]进行rehash的时候使用。rehashidx记录rehash的进度。
3.3、哈希算法是怎样的?
当字典被用作数据库底层实现或者哈希键的底层实现时,Redis使用了MurmurHash2算法来计算键的哈希值;
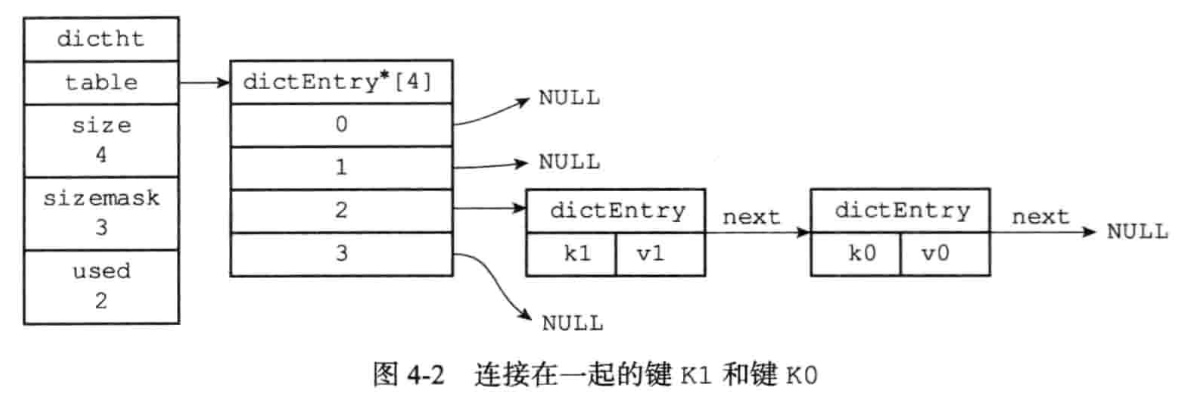
3.4、如何解决键冲突?
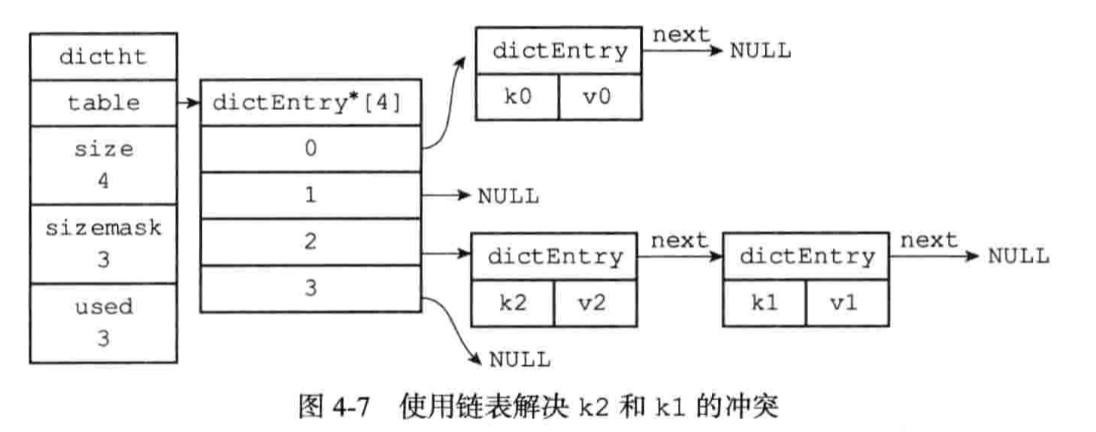
程序总是将新节点添加到链表的表头未知
3.5、为什么要执行rehash,Redis对字典的哈希表执行rehash的过程是怎样的?
随着哈希表的键值对主键增多,为了让负载因子维持在一个合理的范围,当键值对太多或者太少时,需要对哈希表的大小进行相应的扩展或收缩,通过rehash(重新散列)操作来完成.
rehash过程:
- 为ht[1]分配空间(扩展:大小为第一个大于等于ht[0].used*2的2的n次方,收缩:大小为第一个大于等于ht[0].used*2的n次方)
- 将ht[0]中所有键值对rehash到ht[1]
- 迁移完毕之后,释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表
3.6、哈希表的扩展与收缩条件是怎样的?
- 如果服务器没有在执行BGSAVE或者BGREWRITEAOF命令,并且负载因子>=1,则执行扩展操作;
- 如果服务器目前在执行BGSAVE或者BGREWRITEAOF命令,并且负载因子>=5,则执行扩展操作;
执行这两个命令的过程中,Redis需要创建服务器进程的子进程,服务器会提高执行扩展操作所需的负载因子,避免在子进程期间进行哈希表扩展操作; - 当哈希因子<0.1,对哈希表执行收缩操作;
3.7、为什么要渐进式执行rehash?
为了避免rehash对服务器性能造成影响,服务器不是一次性将ht[0]全部hash到ht[1],而是分多次,渐进式地进行。在rehash期间,删除,查找,更新会在两个哈希表上进行,而新增则写入ht[1]。
4、跳跃表
跳跃表支持平均O(logN),最坏O(N)复杂度的节点查找,大部分情况下,跳跃表的效率可以和平衡树相媲美,而跳跃表的实现比平衡树更简单。
4.1、跳跃表用于?
Redis使用跳跃表作为有序集合键的底层实现之一;集群节点中用作内部数据结构。
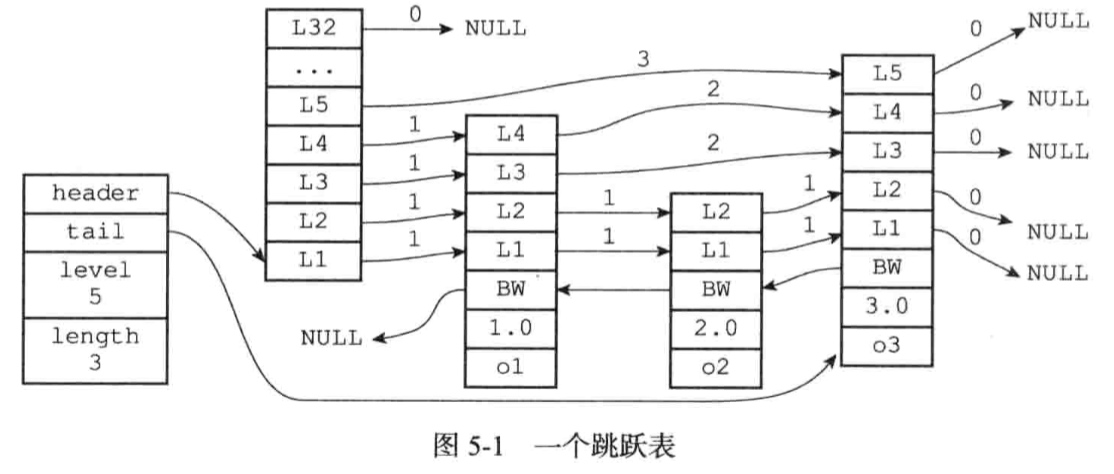
从表头到目标节点,所累计的跨度代表了目标节点在跳跃表中的排位;
后退指针
分值和成员:跳跃表中所有节点都是按照分值从小到大排列的;成员是一个指针,指向一个SDS字符串。
5、整数集合
整数集合是集合键的底层实现之一(当一个集合只包含整数值的时候,并且元素数量不多时)。
各个项在数组中按值的大小从小到大有序地排列,并且不包含任何重复项;
contents数组保存的类型取决于encoding中的值,而不是int8_t;
5.1、什么时候需要升级整数集合
新元素的类型比现有的所有元素的类型都要长的时候会进行升级;每次添加新元素,都有可能导致升级,所以复杂度为O(N)。
5.2、升级的好处
C语言为了避免类型错误,通常不会把不同类型的值放到同一个数据结构里面,通过升级,可以灵活添加不同类型的整数,而不必担心出错;
在适当的是时候,才升级,节约了内存;
整数集合不支持降级操作;
6、压缩列表(ziplist)
6.1、什么时候会使用压缩列表
当一个列表只包含少量列表项,并且每个列表项要么是小整数,要么是长度比较短的字符串,Redis就会使用压缩列表来做列表键的底层实现。
压缩列表是Redis为了节约内存而开发的;
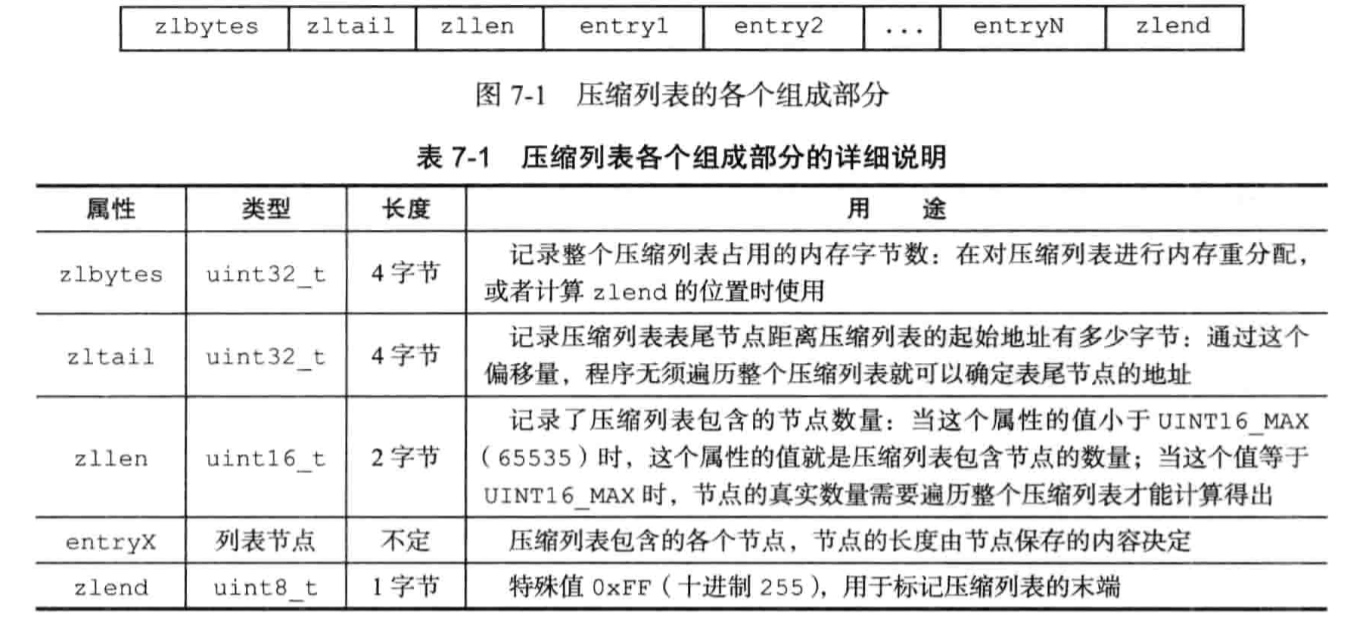
6.2、什么是连锁更新

provious_entry_length记录了压缩列表前一个节点的长度,这个属性为1个字节或者五个字节,如果前一个节点长度小于254字节,则这个属性为一个字节,否则这个属性为五个字节。
如果在一个节点都为小于254字节的压缩链表中间插入一个新的大于254字节的节点A,后一个节点B的previous_entry_length就会从一个属性变为5个属性,从而导致节点B也可能超过254字节…
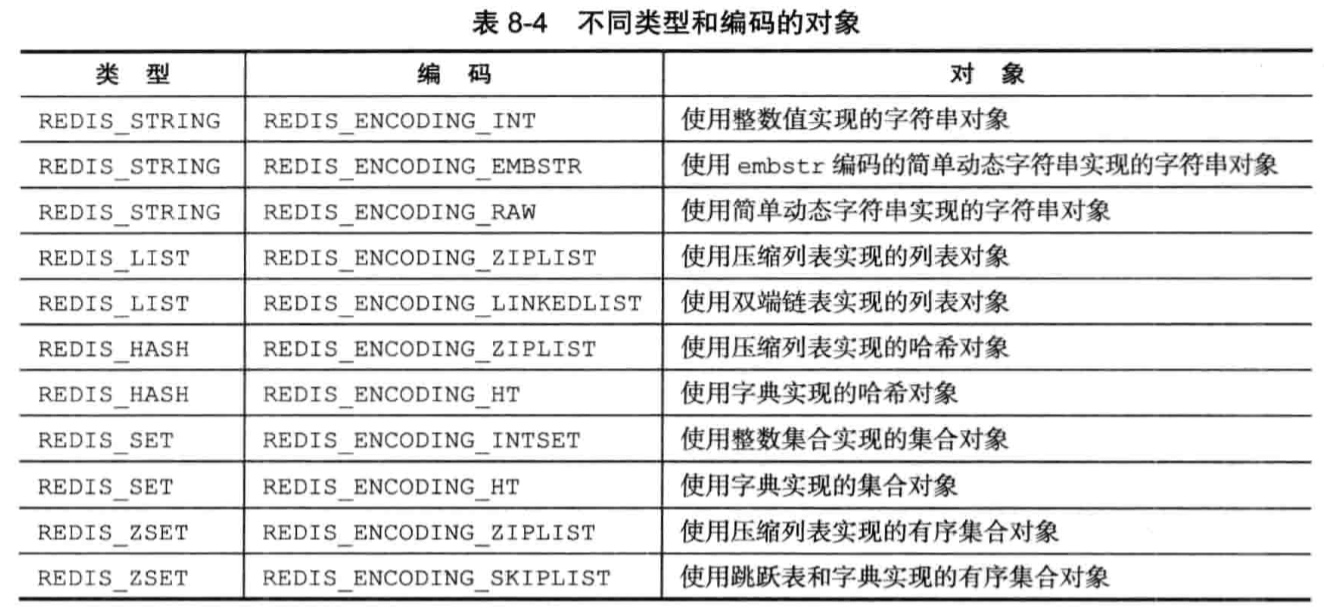
7、对象
Redis没有使用上面的数据结构直接实现数据库,而是基于这些数据结构创建了一个对象系统,包括以下五种类型:
- 字符串对象
- 列表对象
- 哈希对象
- 集合对象
- 有序集合对象
我们可以针对不同的使用场景,为对象设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率。
基于引用计数技术的内存回收机制,回收不再使用的对象,在适当条件下,让多个数据库键共享一个对象来节约内存。
创建对象例子
SET msg “hello world”
会分表为键和值创建redisObject对象:
type
type: REDIS_STRING, REDIS_LIST, REDIS_HASH, REDIS_SET, REDIS_ZSET
redis> TYPE msg
string
不同类型对象的创建
SET msg “hello world” #字符串对象 string
HMSET profile name Jason age 20 career Engineer # 哈希对象hash
SADD fruits apple banana cherry # 集合对象 set
ZADD price 8.5 apple 5.0 banana 6.0 cherry # 有序集合对象 zset
encoding
查看数据库键的值对象的编码:
redis> OBJECT ENCODING msg
7.1、字符串对象
7.1.1、编码问题
字符串对象REDIS_STRING的编码可以是int,raw或者embstr。
例子:
redis> SET number 10000
redis> OBJECT ENCODING number # int
redit> SET story “data structure algorithrm operation system …”
redis> OBJECT ENCODING story # raw 长度大于32个字节
redis> SET msg “hello”
redis> OBJECT ENCODING msg # embstr 长度小于等于32个字节
redis> SET pi 3.14
redis> OBJECT ENCODING pi # embstr

7.1.2、embstr编码的好处
- 创建字符串所需的内存分配次数从raw编码的两次降为一次;
- 释放embstr编码字符串只需要调用一次内存释放,raw需要两次
- embstr编码字符串对象所有数据都保存在一块连续的内存,比raw更好的利用缓存带来的优势
embstr字符串不允许修改,在执行修改命令时会先转换为raw编码。

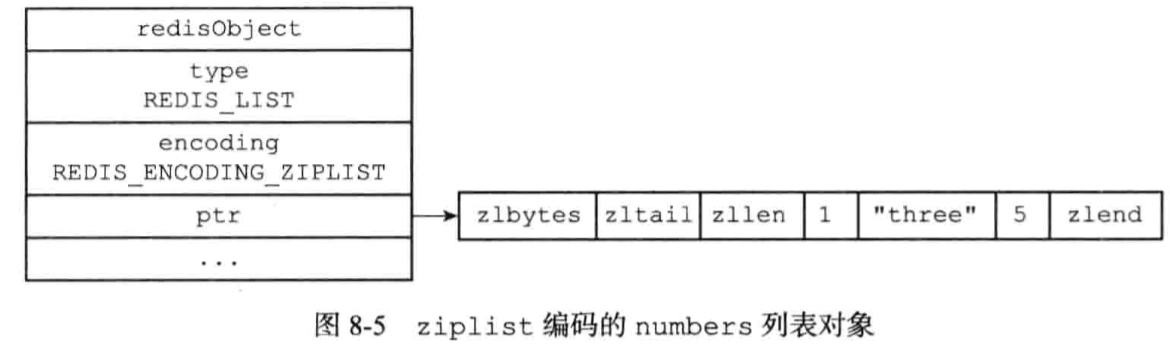
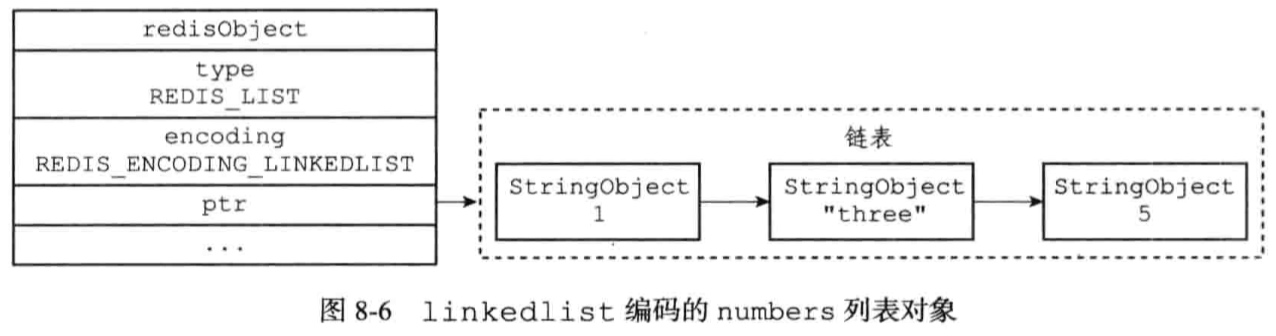
7.2、列表对象
编码:ziplist或者linkedlist
redis> RPUSH numbers 1 “a” 2
字符串对象是Redis五种类型的对象中唯一一种会被其他四中类型对象嵌套的对象。
7.2.1、列表对象的编码转换
使用ziplist编码的条件:
- 列表对象保存的所有字符串元素的长度都小于64字节
- 列表元素小于512个
以上上限可修改(list-max-ziplist-value list-max-ziplist-entries)
7.3、哈希对象
编码:ziplist或者hashtable
7.3.1、ziplist格式的编码
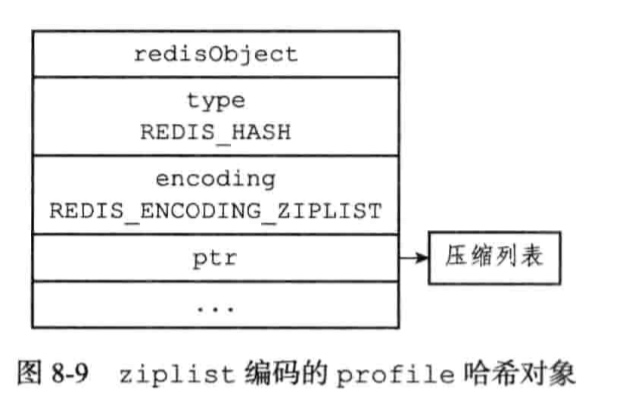

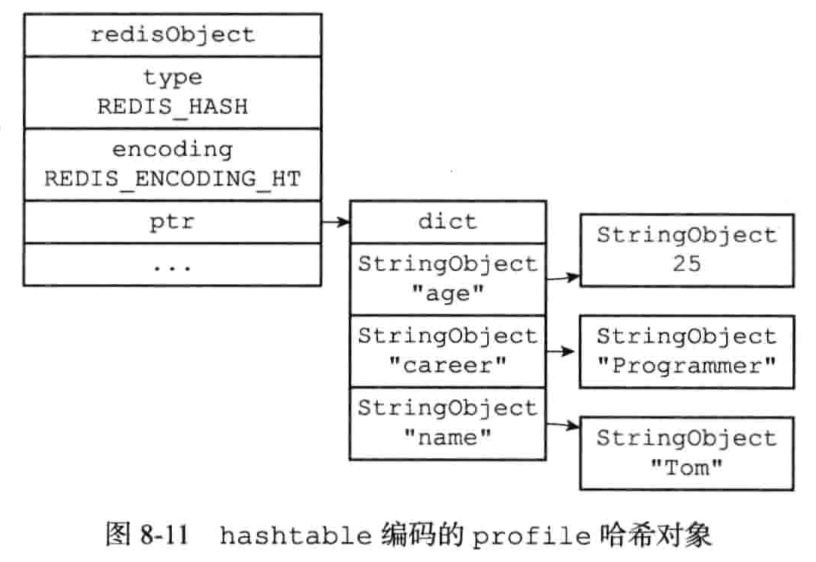
7.3.2、hashtable格式的编码
字典的键和值都是字符串对象
7.3.3、hash对象的编码转换
使用ziplist对象的条件:
- 哈希对象保存的所有键值字符串长度都小于64字节;
- 哈希对象保存的键值对数量小于512;
以上上限可修改(hash-max-ziplist-value hash-max-ziplist-entries)
7.4、集合对象
集合对象的编码:intset或者hashtable
7.4.1、intset
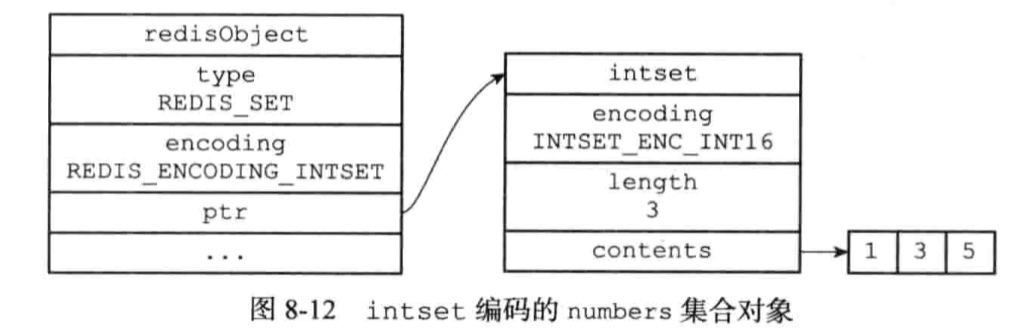
集合对象包含的所有元素都被保存在整数集合里面;
7.4.2、hashtable
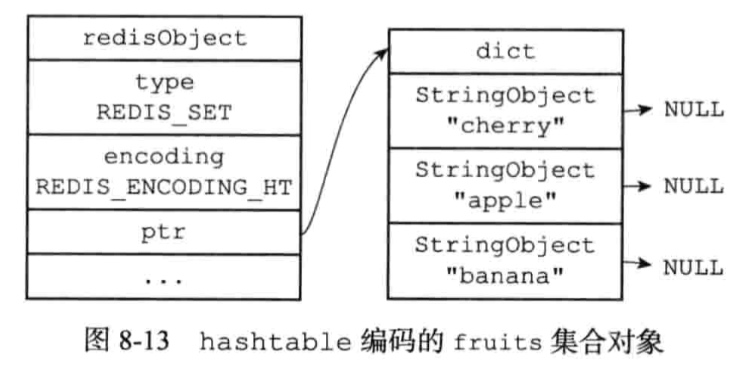
hashtable使用字典作为底层实现,字典的值全部设置为NULL。
7.4.3、集合对象的编码转换
使用intset对象的条件:
- 集合对象保存的所有元素都是整数值;
- 元素个数不超过512。
上限可以修改(set-max-intset-entries)
7.4、有序集合对象
编码:ziplist或者skiplist
7.4.1、ziplist
每个集合使用紧挨着的两个压缩列表节点来表示,第一个节点保存元素成员,第二个元素保存元素的分值;按分值从小到大进行排列;
7.4.2、skiplist
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset同时包含一个字典和一个跳跃表:
1 | typedef struct zset { |
为什么同事使用跳跃表和字典来实现有序集合
单独通过字典或者跳跃表来实现有序集合,性能都会有所下降。
字典和跳跃表会共享元素的成员和分值,所以并不会造成任何数据重复,也不会因此而浪费内存。
7.4.3、编码转换
使用ziplist的条件:
- 有序集合的元素数量小于128个
- 有序集合保存的所有元素成员长度都小于64字节
修改参数:zset-max-ziplist-entries,zset-max-ziplist-value。
7.5、类型检查与命令多态
Redis用于操作键的命令可以分为两种:
- 可以对任何类型的键执行:DEL,EXPIRE,RENAME,TYPE,OBJECT
- 只能对特定类型的键执行:
字符串对象:SET,GET,APPEND,STRLEN
哈希对象:HDEL,HSET,HGET,HLEN
列表对象:RPUSH,LPOP,LINSERT,LLEN
集合对象:SADD,SPOP,SINSERT,SCARD
有序集合对象:ZADD,ZCARD,ZRANK,ZSCORE
对于第二类命令,在执行之前,需要先执行类型检查,通过redisObject结构的type属性来实现的。
每一种类型的对象,底层的编码是不一样的,执行同样的LLEN命令,底层是ziplist还是linkedlist编码,需要确保命令都可以正常运行,这就是命令的多态(包括可以对任何类型的键执行的命令)。
7.6、内存回收
通过Redis系统内构建的引用计数器来实现内存回收
7.7、对象共享
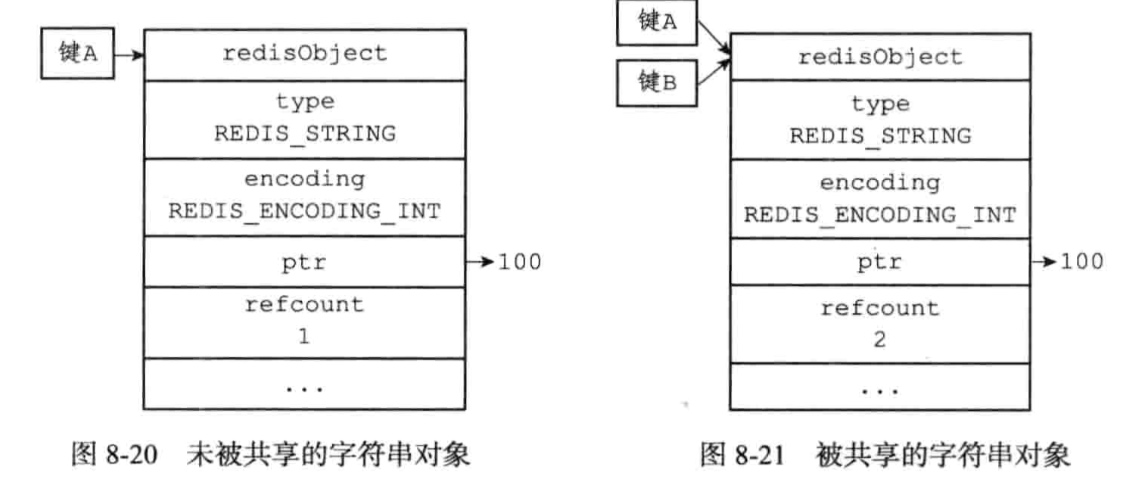
被共享的的对象,引用计数器会对应+1。
Redis在启动的时候会创建一万个字符串对象,这些字符串对象包含了从0到9999的所有整数值,通过共享对象方式使用这些值,而不是新创建对象。
修改初始化的共享对象个数:redis.h/REDIS_SHARED_INTEGERS
查看引用计数:
redis> OBJECT REFCOUNT obj
为什么Redis不共享包含字符串的对象?
将一个共享对象设置为键的值对象时,程序会先进行检查校验想要创建的对象和目标对象是否完全一致:
- 如果共享对象保存整数值,验证复杂度为O(1)
- 如果共享对象是保存字符串值的字符串对象,验证复杂度为O(N)
- 如果共享对象是包含了多个值的对象,那么验证操作的复杂度将会是O(N^2)
收到CPU时间的限制,Redis只对包含整数值的字符串进行共享。
7.8、对象的空转时长

redisObject对象的lru属性记录了对象最后一次被命令程序访问的时间。
如果服务器打开了maxmemory选项,并且服务器用户回收内存的算法为volatile-lru或者allkeys-lru,那么服务器占用的内存数超过了maxmemory选项所设置的上限值时,空转时长较高的那部分键就会优先被服务器释放。
References
本文来源于《Redis设计与实现》,笔记摘要与相关问题思考。