ZooKeeper的数据变更通知的流程
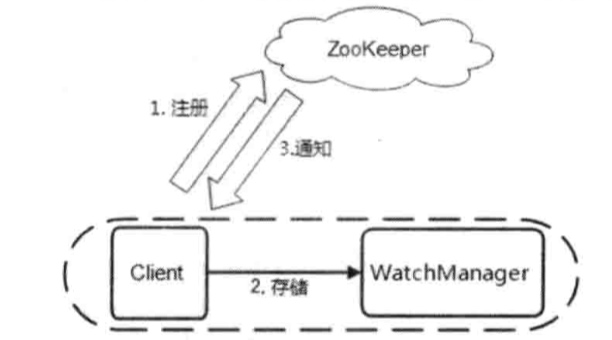
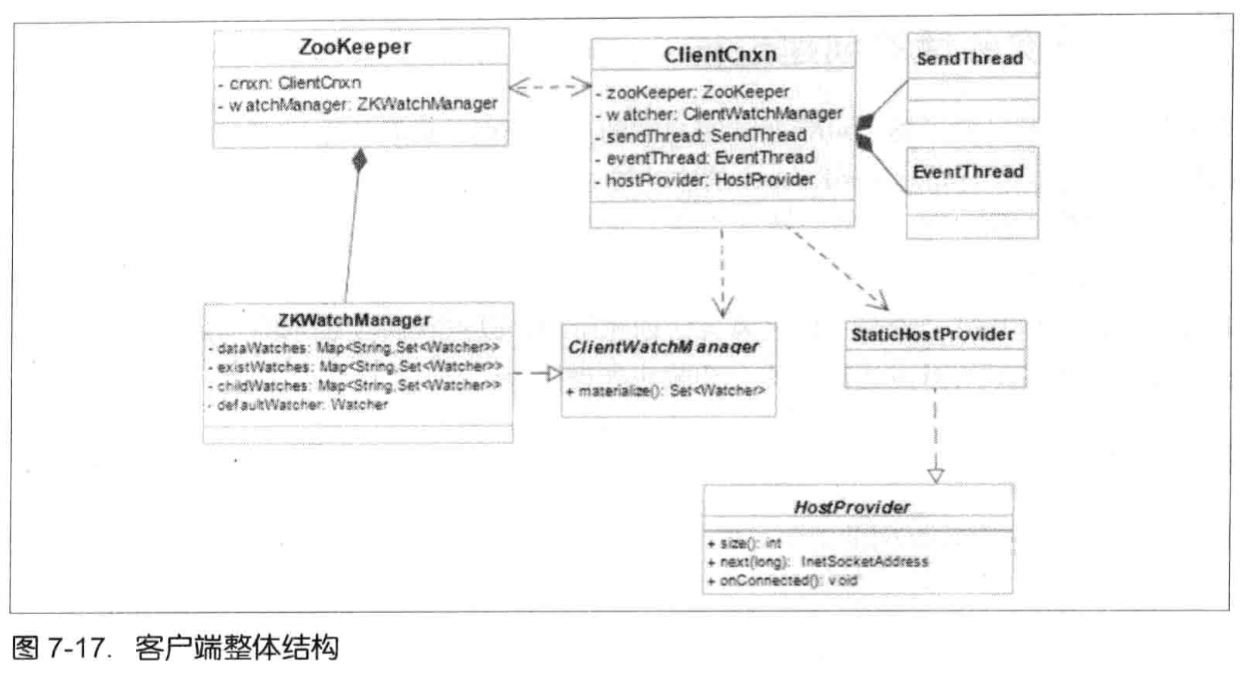
Client向Zk注册Watcher,同时将Watcher对象存储在客户端的WatchManger中,服务器端先生成WatcherEvent事件对象,序列化传输,客户端把WatcherEvent还原成WatchedEvent对象,调用Watcher中的回调函数进行处理:process(WatchedEvent event);
下面看看Watcher的注册流程:
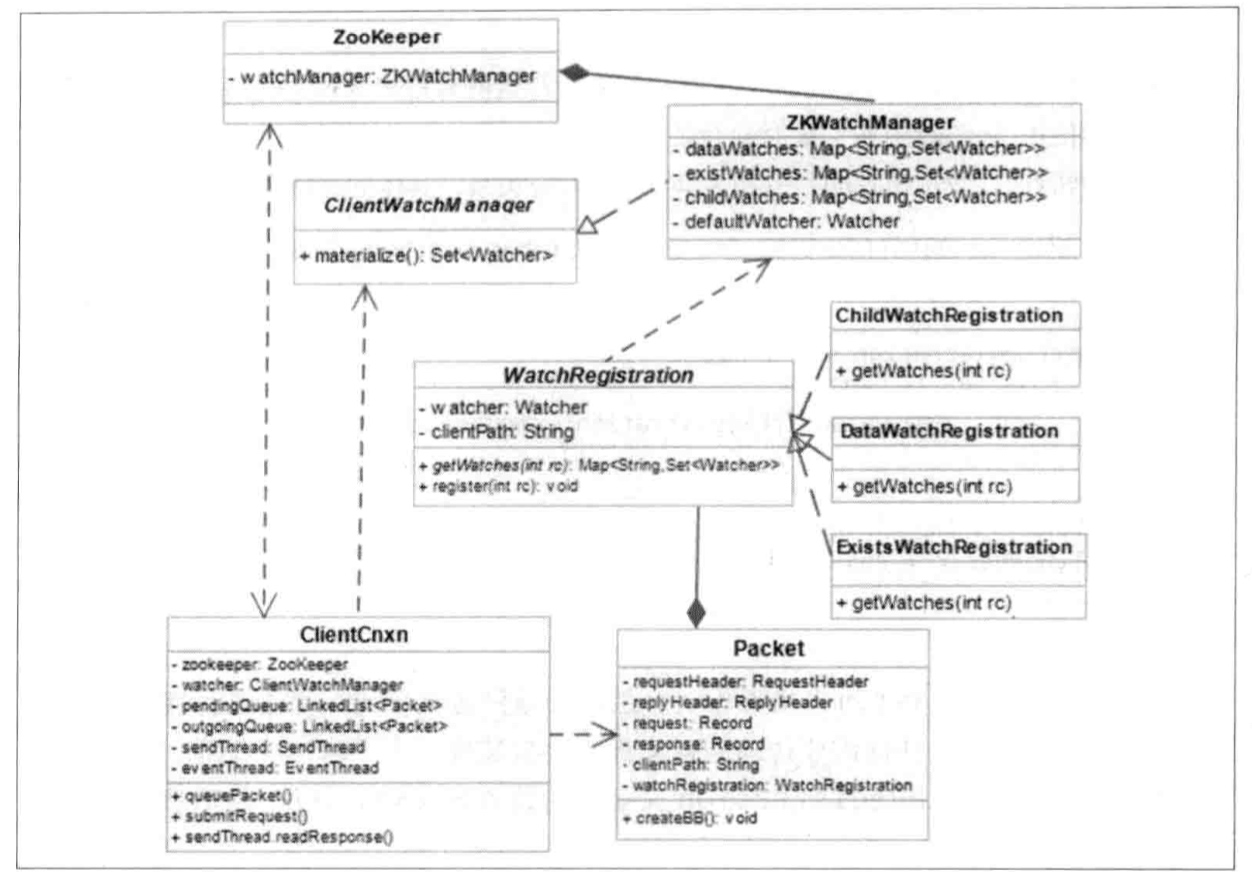
创建ZooKeeper客户端实例的时候(getData,getChildren,exist也可以)传入Watcher,会一直保存在客户端ZKWatchManager的defaultWatcher中,作为整个ZooKeeper会话期间的默认Watcher。
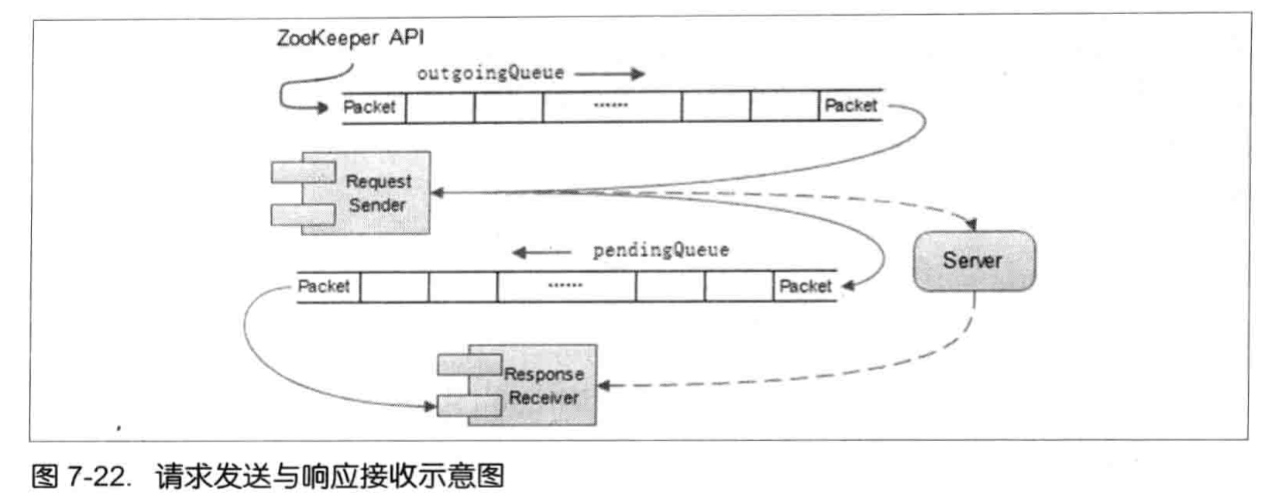
客户端发送Watcher:
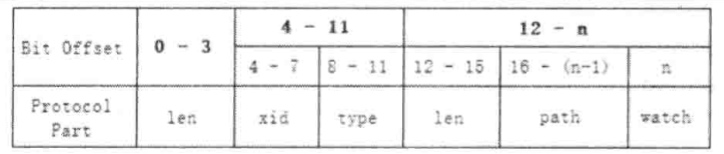
标记request为使用Watcher监听 --> 封装WatchRegistration对象(保存数据节点和Watcher的对应关系) --> 在ClientCnxn把WatchRegistration封装到Packet中 --> 放入发送队列等待客户端发送 --> SendThread.readResponse方法负责接收来自服务端的响应 --> finishPacket方法从Packet中取出对应的Watcher注册到ZKWatchManger中。(从WatchRegistration对象中提取出Watcher,保存在ZKWatchManger的dataWatches中,dataWatches的key是数据节点的路径。)
底层实际传输的过程中,并没有将WatchRegistration序列化到底层数组中。
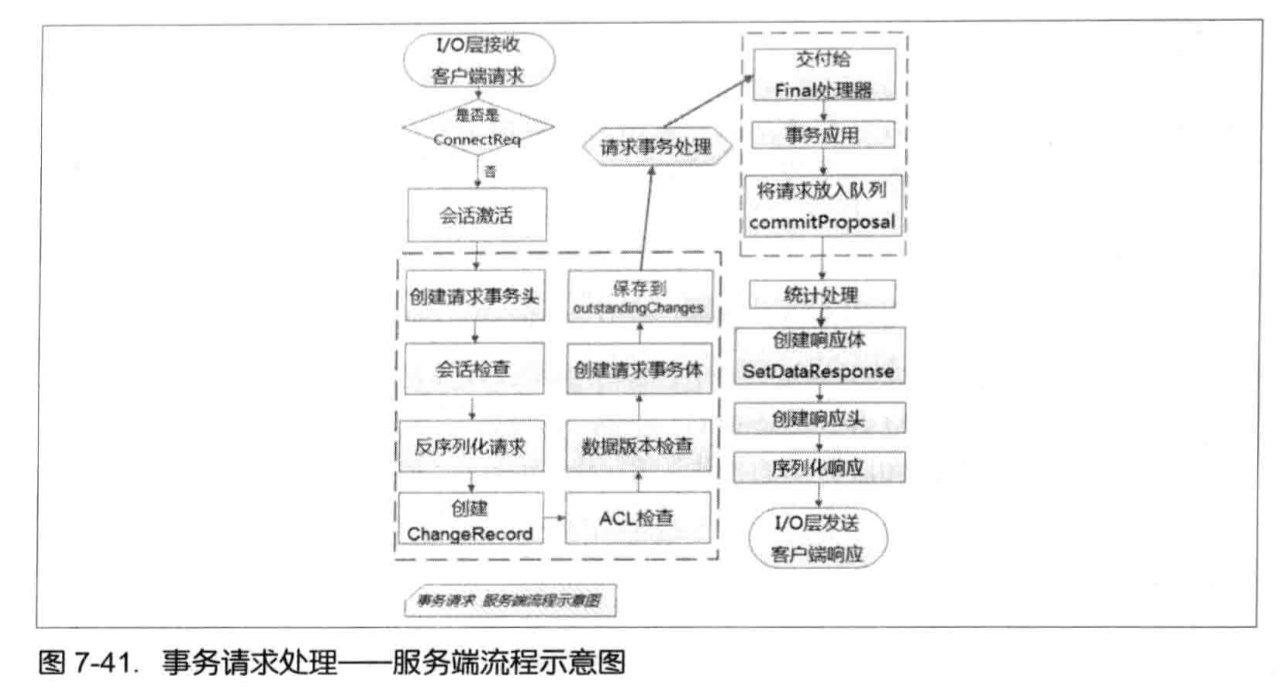
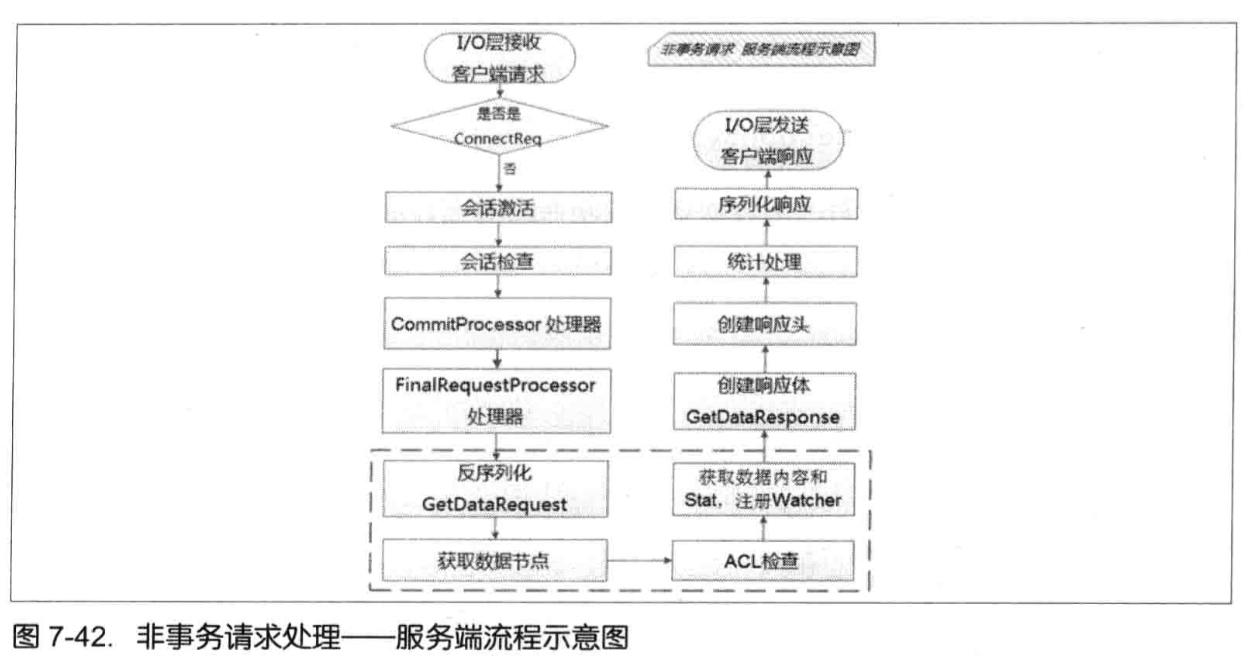
服务器端处理Watcher:
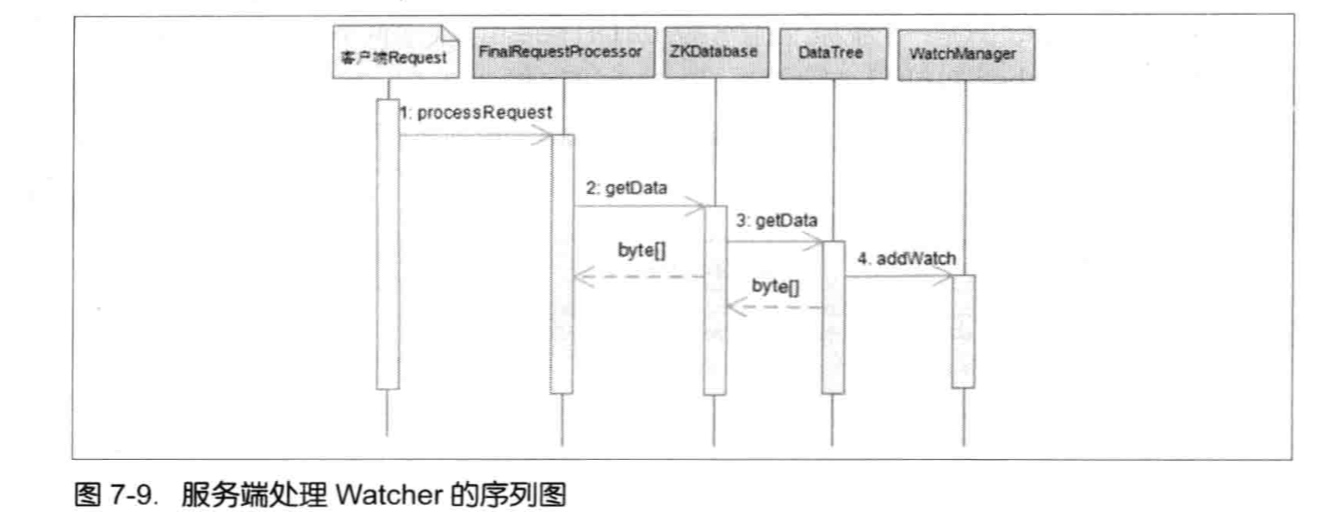
FinalRequestProcessor.processRequest中判断是否需要注册Watcher --> 需要注册,则将ServerCnxn对象和数据节点路径传入getData方法。(ServerCnxn代表着一个客户端和服务器的连接,实现:NIOServerCnxn,NettyServerCnxn,并实现了process方法,可以把ServerCnxn看成Watcher对象) --> 数据节点路径和ServerCnxn最终存储在WatchManger的WatchTable和watch2Paths中。
Watcher事件触发:
WatchManager负责Watcher事件触发,并移除已经被触发的Watcher:
- 封装WatchedEvent
- 查询Watcher
- 调用ServerCnxn的process方法来触发
请求头是-1,表明当前是一个通知;
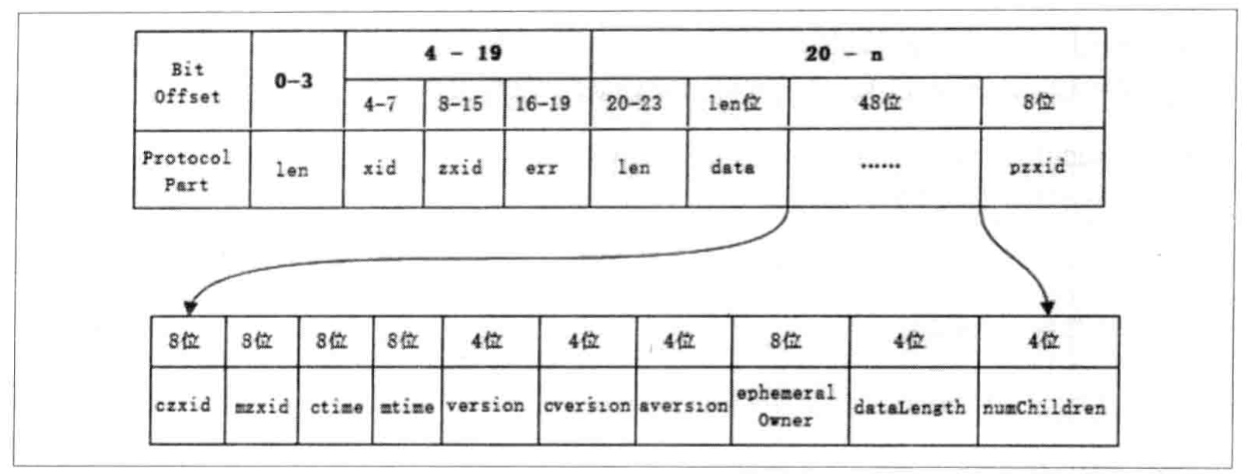
将WatchedEvent包装成WatcherEvent对象,以便于网络传输序列化;
向客户端发送通知
客户端回调Watcher:
SendThread.readResponse()接收事件通知,如果响应头标识了XID为-1,则表明是一个通知类型的响应,处理流程:
反序列化;
处理chrootPath;
还原WatchedEvent;
回调Watcher;
Watcher特性:
一次性;
客户端串行执行;
轻量;