Author: ChinSyun Pang
Weibo: arthinking_plus
Posted in: http://www.itzhai.com
1、配置
1.1、安装
1 | sudo apt-get install memcached |
1.2、启动
Memcached的基本设置:
-p 监听的端口
-l 连接的IP地址, 默认是本机
-d start 启动memcached服务
-d restart 重起memcached服务
-d stop|shutdown 关闭正在运行的memcached服务
-d install 安装memcached服务
-d uninstall 卸载memcached服务
-u 以的身份运行 (仅在以root运行的时候有效)
-m 最大内存使用,单位MB。默认64MB
-M 内存耗尽时返回错误,而不是删除项
-c 最大同时连接数,默认是1024
-f 块大小增长因子,默认是1.25
-n 最小分配空间,key+value+flags默认是48
-h 显示帮助
mixi的设置,单台:
1 | # 每台mc服务器仅启动一个mc进程,分配1G内存 |
2.1.2、编译安装Memcached:
1 | wget http://danga.com/memcached/dist/memcached-1.2.6.tar.gz |
2.1.3、编译安装magent:
1 | mkdir magent |
2.1.4、集群配置
集群两台服务器,实现缓存备份。
高可用网络架构: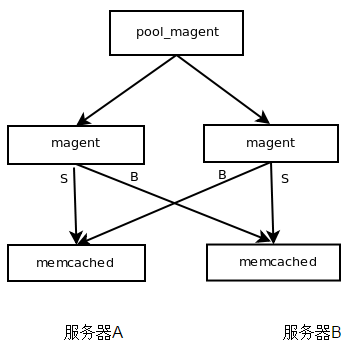
启动两个mc进程,端口分别为11211,112121
2memcached -m 1 -u root -d -l 127.0.0.1 -p 11211
memcached -m 1 -u root -d -l 127.0.0.1 -p 11212
启动两个magent进程,端口分别为10000,100011
2magent -u root -n 51200 -l 127.0.0.1 -p 10000 -s 127.0.0.1:11211 -b 127.0.0.1:11212
magent -u root -n 51200 -l 127.0.0.1 -p 10001 -s 127.0.0.1:11212 -b 127.0.0.1 11211
-s为要写入的memcached,-b为备份用的memcached
3、使用
3.1、清空缓存
1 | telnet 127.0.0.1 11211 |
4、监控
4.1、stats
1 | telnet 127.0.0.1 11211 |
相关资源: